Build Earthquake Catalog
In this final notebook, we read the matched-filter database, remove the multiple detections and write a clean earthquake catalog in a csv file.
[1]:
import os
n_CPUs = 12
os.environ["OMP_NUM_THREADS"] = str(n_CPUs)
import BPMF
import glob
import h5py as h5
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sys
import seisbench.models as sbm
from BPMF.data_reader_examples import data_reader_mseed
from tqdm import tqdm
from time import time as give_time
pd.set_option('display.width', 1000)
[2]:
# PROGRAM PARAMETERS
NETWORK_FILENAME = "network.csv"
TEMPLATE_DB = "template_db"
MATCHED_FILTER_DB = "matched_filter_db"
OUTPUT_CSV_FILENAME = "final_catalog.csv"
OUTPUT_DB_FILENAME = "final_catalog.h5"
BACKPROJ_DB_FILENAME = "reloc_bp.h5"
CHECK_SUMMARY_FILE = False
PATH_MF = os.path.join(BPMF.cfg.OUTPUT_PATH, MATCHED_FILTER_DB)
DATA_FOLDER = "preprocessed_2_12"
[3]:
# read network metadata
net = BPMF.dataset.Network(NETWORK_FILENAME)
net.read()
Read the detected events’ metadata for each template
[4]:
# template filenames
template_filenames = glob.glob(os.path.join(BPMF.cfg.OUTPUT_PATH, TEMPLATE_DB, "template*"))
template_filenames.sort()
# initialize the template group
template_group = BPMF.dataset.TemplateGroup.read_from_files(template_filenames, net)
template_group.read_catalog(
extra_attributes=["cc"],
progress=True,
db_path=PATH_MF,
check_summary_file=CHECK_SUMMARY_FILE,
)
# sometimes, tid is not cast to the correct dtype
template_group.catalog.catalog["tid"] = template_group.catalog.catalog["tid"].astype("int32")
Reading catalog: 100%|██████████| 10/10 [00:00<00:00, 22.38it/s]
The BPMF.dataset.TemplateGroup now has a catalog attribute, which is a BPMF.dataset.Catalog instance.
Remove the multiple detections
Remove multiple detections with the TemplateGroup.remove_multiples method.
[5]:
# DISTANCE_CRITERION_KM: Distance, in km, between two detected events (within uncertainties) below which
# detected events are investigated for equality.
DISTANCE_CRITERION_KM = 15.0
# DT_CRITERION_SEC: Inter-event time, in seconds, between two detected events below which
# detected events are investigated for redundancy.
DT_CRITERION_SEC = 4.0
# SIMILARITY_CRITERION: Inter-template correlation coefficient below which detected events are investigated for equality.
SIMILARITY_CRITERION = 0.10
# N_CLOSEST_STATIONS: When computing the inter-template correlation coefficient, use the N_CLOSEST_STATIONS closest stations
# of a given pair of templates. This parameter is relevant for studies with large seismic networks.
N_CLOSEST_STATIONS = 10
[6]:
# we need to read the waveforms first
template_group.read_waveforms()
template_group.normalize(method="rms")
[7]:
template_group.remove_multiples(
n_closest_stations=N_CLOSEST_STATIONS,
dt_criterion=DT_CRITERION_SEC,
distance_criterion=DISTANCE_CRITERION_KM,
similarity_criterion=SIMILARITY_CRITERION,
progress=True,
)
/home/ebeauce/software/Seismic_BPMF/BPMF/dataset.py:4624: RuntimeWarning: invalid value encountered in divide
unit_direction /= np.sqrt(np.sum(unit_direction**2, axis=1))[:, np.newaxis]
False ../BPMF_outputs/template_db/intertp_cc.h5 False
Computing the similarity matrix...
Computing the inter-template directional errors...
Searching for events detected by multiple templates
All events occurring within 4.0 sec, with uncertainty ellipsoids closer than 15.0 km will and inter-template CC larger than 0.10 be considered the same
Removing multiples: 100%|██████████| 141/141 [00:00<00:00, 2969.63it/s]
0.05s to flag the multiples
The catalog now has three new columns: origin_time_sec (a timestamp of origin_time in seconds), interevent_time_sec (template-wise computation), unique_event.
[8]:
template_group.catalog.catalog.head(10)
[8]:
| longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | |
|---|---|---|---|---|---|---|---|---|---|---|
| event_id | ||||||||||
| 3.0 | 30.324023 | 40.723125 | 9.5 | 2012-07-26 00:58:11.040 | 0.228311 | 3 | NaN | 1.343264e+09 | 0.00 | False |
| 7.0 | 30.343555 | 40.716875 | 9.1 | 2012-07-26 00:58:11.040 | 0.341836 | 7 | NaN | 1.343264e+09 | 0.00 | True |
| 0.0 | 30.337695 | 40.718125 | 9.3 | 2012-07-26 00:58:11.080 | 0.319705 | 0 | NaN | 1.343264e+09 | 0.04 | False |
| 1.0 | 30.284961 | 40.670625 | 10.9 | 2012-07-26 00:58:11.480 | 0.330284 | 1 | NaN | 1.343264e+09 | 0.40 | False |
| 3.1 | 30.324023 | 40.723125 | 9.5 | 2012-07-26 00:58:16.600 | 0.202776 | 3 | 5.56 | 1.343264e+09 | 5.12 | False |
| 0.1 | 30.337695 | 40.718125 | 9.3 | 2012-07-26 00:58:16.600 | 0.263212 | 0 | 5.52 | 1.343264e+09 | 0.00 | False |
| 7.1 | 30.343555 | 40.716875 | 9.1 | 2012-07-26 00:58:16.600 | 0.268420 | 7 | 5.56 | 1.343264e+09 | 0.00 | True |
| 3.2 | 30.324023 | 40.723125 | 9.5 | 2012-07-26 01:02:53.360 | 0.194579 | 3 | 276.76 | 1.343265e+09 | 276.76 | False |
| 0.2 | 30.337695 | 40.718125 | 9.3 | 2012-07-26 01:02:53.360 | 0.266884 | 0 | 276.76 | 1.343265e+09 | 0.00 | True |
| 7.2 | 30.343555 | 40.716875 | 9.1 | 2012-07-26 01:03:46.960 | 0.243300 | 7 | 330.36 | 1.343265e+09 | 53.60 | False |
The final catalog is made of the unique events only.
[9]:
template_group.catalog.catalog = template_group.catalog.catalog[template_group.catalog.catalog["unique_event"]]
initial_catalog = template_group.catalog.catalog.copy()
[10]:
print(f"There are {len(template_group.catalog.catalog)} events in our template matching catalog!")
template_group.catalog.catalog
There are 54 events in our template matching catalog!
[10]:
| longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | |
|---|---|---|---|---|---|---|---|---|---|---|
| event_id | ||||||||||
| 7.0 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 00:58:11.040 | 0.341836 | 7 | NaN | 1.343264e+09 | 0.00 | True |
| 7.1 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 00:58:16.600 | 0.268420 | 7 | 5.56 | 1.343264e+09 | 0.00 | True |
| 0.2 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:02:53.360 | 0.266884 | 0 | 276.76 | 1.343265e+09 | 0.00 | True |
| 0.3 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:03:47.000 | 0.404978 | 0 | 53.64 | 1.343265e+09 | 0.04 | True |
| 7.3 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 01:09:25.920 | 0.289663 | 7 | 338.96 | 1.343265e+09 | 338.92 | True |
| 0.5 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:10:22.240 | 0.714110 | 0 | 56.28 | 1.343265e+09 | 0.16 | True |
| 7.5 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 01:10:44.000 | 0.590040 | 7 | 21.76 | 1.343265e+09 | 0.00 | True |
| 0.7 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:12:32.960 | 0.317964 | 0 | 108.92 | 1.343265e+09 | 0.04 | True |
| 0.8 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:15:14.840 | 0.581384 | 0 | 161.88 | 1.343265e+09 | 0.04 | True |
| 0.9 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:15:22.400 | 0.332889 | 0 | 7.56 | 1.343265e+09 | 0.04 | True |
| 0.10 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:15:35.160 | 0.286360 | 0 | 12.76 | 1.343265e+09 | 0.00 | True |
| 0.11 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:15:54.240 | 1.000000 | 0 | 19.08 | 1.343265e+09 | 0.04 | True |
| 0.12 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:16:30.080 | 0.331540 | 0 | 35.84 | 1.343265e+09 | 0.00 | True |
| 0.13 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:18:32.960 | 0.257836 | 0 | 122.88 | 1.343266e+09 | 122.44 | True |
| 1.8 | 30.284961 | 40.670625 | 10.900 | 2012-07-26 01:35:15.120 | 0.247586 | 1 | 1124.60 | 1.343267e+09 | 0.44 | True |
| 0.14 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:39:53.760 | 0.226896 | 0 | 1280.80 | 1.343267e+09 | 278.64 | True |
| 3.12 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 01:52:27.920 | 0.206768 | 3 | 2034.96 | 1.343268e+09 | 754.16 | True |
| 0.15 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:52:36.520 | 0.392199 | 0 | 762.76 | 1.343268e+09 | 0.04 | True |
| 7.13 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 02:22:49.880 | 0.236185 | 7 | 1813.40 | 1.343269e+09 | 0.00 | True |
| 0.17 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 02:24:35.000 | 0.468882 | 0 | 105.12 | 1.343269e+09 | 0.04 | True |
| 1.11 | 30.284961 | 40.670625 | 10.900 | 2012-07-26 02:35:01.560 | 1.000000 | 1 | 626.12 | 1.343270e+09 | 0.44 | True |
| 0.19 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 03:00:38.960 | 0.513174 | 0 | 1537.84 | 1.343272e+09 | 0.00 | True |
| 3.18 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 03:08:33.520 | 0.411021 | 3 | 474.56 | 1.343272e+09 | 0.00 | True |
| 3.19 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 03:10:55.040 | 0.325226 | 3 | 141.52 | 1.343272e+09 | 141.48 | True |
| 3.20 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 04:30:33.520 | 0.190873 | 3 | 4778.48 | 1.343277e+09 | 4778.48 | True |
| 2.4 | 30.323047 | 40.723750 | 10.600 | 2012-07-26 04:43:38.240 | 1.000000 | 2 | 5704.84 | 1.343278e+09 | 784.72 | True |
| 7.19 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 04:45:03.920 | 0.275260 | 7 | 5648.88 | 1.343278e+09 | 85.52 | True |
| 2.5 | 30.323047 | 40.723750 | 10.600 | 2012-07-26 04:46:49.160 | 0.323422 | 2 | 190.92 | 1.343278e+09 | 104.80 | True |
| 2.6 | 30.323047 | 40.723750 | 10.600 | 2012-07-26 04:48:38.480 | 0.355615 | 2 | 109.32 | 1.343278e+09 | 109.32 | True |
| 2.7 | 30.323047 | 40.723750 | 10.600 | 2012-07-26 04:51:06.520 | 0.344914 | 2 | 148.04 | 1.343278e+09 | 147.88 | True |
| 3.24 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 05:22:04.440 | 0.284165 | 3 | 1857.76 | 1.343280e+09 | 1857.76 | True |
| 3.25 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 05:45:46.000 | 0.184268 | 3 | 1421.56 | 1.343282e+09 | 1421.56 | True |
| 3.26 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 05:46:59.240 | 0.267884 | 3 | 73.24 | 1.343282e+09 | 73.24 | True |
| 3.27 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 05:57:16.440 | 0.215643 | 3 | 617.20 | 1.343282e+09 | 617.20 | True |
| 3.28 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 08:08:25.640 | 1.000000 | 3 | 7869.20 | 1.343290e+09 | 0.16 | True |
| 4.0 | 30.341602 | 40.716875 | 8.900 | 2012-07-26 09:21:39.360 | 0.206163 | 4 | NaN | 1.343294e+09 | 4393.28 | True |
| 4.1 | 30.341602 | 40.716875 | 8.900 | 2012-07-26 09:28:48.320 | 0.174172 | 4 | 428.96 | 1.343295e+09 | 428.96 | True |
| 4.2 | 30.341602 | 40.716875 | 8.900 | 2012-07-26 10:07:23.680 | 1.000000 | 4 | 2315.36 | 1.343297e+09 | 2315.36 | True |
| 3.29 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 10:16:45.760 | 0.358623 | 3 | 7700.12 | 1.343298e+09 | 0.00 | True |
| 3.30 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 10:53:46.560 | 0.240390 | 3 | 2220.80 | 1.343300e+09 | 2220.80 | True |
| 3.31 | 30.324023 | 40.723125 | 9.500 | 2012-07-26 11:02:23.560 | 0.350023 | 3 | 517.00 | 1.343301e+09 | 0.12 | True |
| 5.0 | 30.256641 | 40.631250 | 3.000 | 2012-07-26 11:55:35.640 | 1.000000 | 5 | NaN | 1.343304e+09 | 3192.04 | True |
| 6.0 | 30.297168 | 40.799687 | -1.950 | 2012-07-26 13:35:26.160 | 1.000000 | 6 | NaN | 1.343310e+09 | 5990.52 | True |
| 0.25 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 13:48:32.760 | 0.643244 | 0 | 9969.16 | 1.343311e+09 | 0.04 | True |
| 0.26 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 13:50:18.560 | 0.324168 | 0 | 105.80 | 1.343311e+09 | 0.04 | True |
| 7.24 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 13:51:58.600 | 0.537169 | 7 | 100.08 | 1.343311e+09 | 0.00 | True |
| 0.28 | 30.337695 | 40.718125 | 9.300 | 2012-07-26 13:53:31.640 | 0.684881 | 0 | 93.04 | 1.343311e+09 | 0.04 | True |
| 7.26 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 13:54:54.200 | 0.408825 | 7 | 82.60 | 1.343311e+09 | 82.16 | True |
| 7.27 | 30.343555 | 40.716875 | 9.100 | 2012-07-26 13:56:54.240 | 1.000000 | 7 | 120.04 | 1.343311e+09 | 119.60 | True |
| 2.13 | 30.323047 | 40.723750 | 10.600 | 2012-07-26 14:38:50.440 | 0.240563 | 2 | 2718.96 | 1.343314e+09 | 2515.76 | True |
| 8.0 | 30.326709 | 40.600156 | -1.975 | 2012-07-26 15:06:20.040 | 1.000000 | 8 | NaN | 1.343315e+09 | 1649.60 | True |
| 4.3 | 30.341602 | 40.716875 | 8.900 | 2012-07-26 16:26:52.520 | 0.251527 | 4 | 22768.84 | 1.343320e+09 | 4832.48 | True |
| 4.4 | 30.341602 | 40.716875 | 8.900 | 2012-07-26 16:33:57.640 | 0.171122 | 4 | 425.12 | 1.343320e+09 | 425.12 | True |
| 9.0 | 30.408984 | 40.711250 | 5.800 | 2012-07-26 17:28:20.240 | 1.000000 | 9 | NaN | 1.343324e+09 | 3262.60 | True |
Let’s plot these events on a map. You will see that there are far fewer dots on the map than the total number of earthquakes in our catalog… This is because all newly detected events are attributed their template locations. Therefore, most events are plotted at the exact same location.
[11]:
fig = template_group.catalog.plot_map(
figsize=(10, 10), network=net, s=50, markersize_station=50, lat_margin=0.02, plot_uncertainties=False
)
ax = fig.get_axes()[0]
ax.set_facecolor("dimgrey")
ax.patch.set_alpha(0.15)
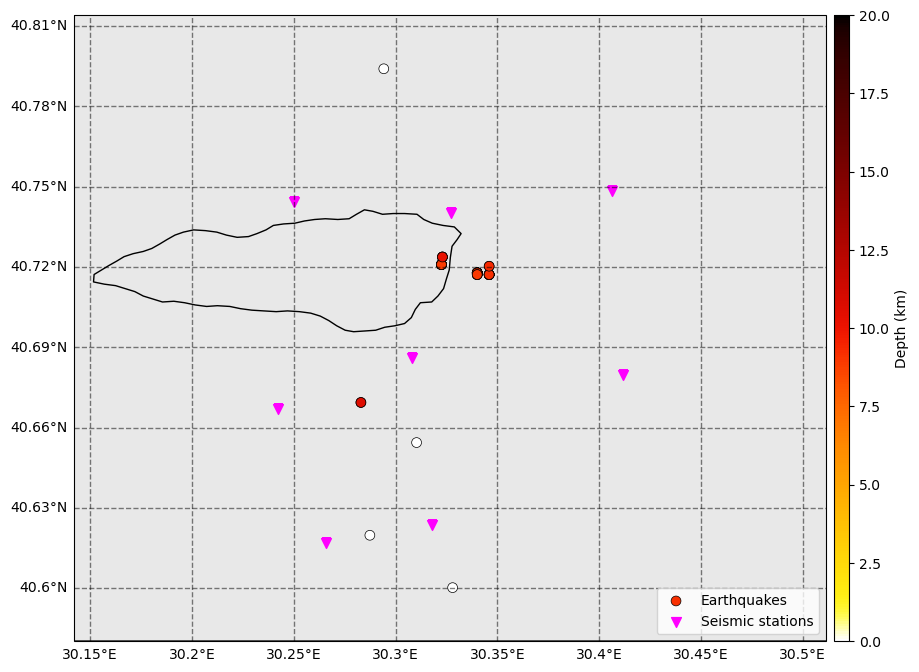
Bonus: Relocate each events
In your workflow, you might be ok with the approximate locations of the template matching catalog. However, if you decide to keep refining the catalog, here are some suggestions to get started.
One possibility to start refining the locations of all events is to re-run the same process as in notebook 6, namely PhaseNet and NonLinLoc.
[12]:
# PhaseNet picking parameters
# PhaseNet was trained for 100Hz data. Even if we saw that running PhaseNet on 25Hz data
# was good for backprojection, here, picking benefits from running PhaseNet on 100Hz data.
# Thus, we will upsample the waveforms before running PhaseNet.
PHASENET_SAMPLING_RATE_HZ = 100.
UPSAMPLING_BEFORE_PN_RELOCATION = int(PHASENET_SAMPLING_RATE_HZ/BPMF.cfg.SAMPLING_RATE_HZ)
DOWNSAMPLING_BEFORE_PN_RELOCATION = 1
# DURATION_SEC: the duration, in seconds, of the data stream starting at the detection time
# defined by Event.origin_time. This data stream is used for picking the P/S waves.
DURATION_SEC = 60.0
# THRESHOLD_P: probability of P-wave arrival above which we declare a pick. If several picks are
# declared during the DURATION_SEC data stream, we only keep the best one. We can
# afford using a low probability threshold since we already know with some confidence
# that an earthquake is in the data stream.
THRESHOLD_P = 0.10
# THRESHOLD_S: probability of S-wave arrival above which we declare a pick.
THRESHOLD_S = 0.10
# DATA_FOLDER: name of the folder where the waveforms we want to use for picking are stored
DATA_FOLDER = "preprocessed_2_12"
# COMPONENT_ALIASES: A dictionary that defines the possible channel names to search for
# for example, the seismometer might not be oriented and the horizontal channels
# might be named 1 and 2, in which case we arbitrarily decide to take 1 as the "N" channel
# and 2 as the "E" channel. This doesn't matter for picking P- and S-wave arrival times.
COMPONENT_ALIASES = {"N": ["N", "1"], "E": ["E", "2"], "Z": ["Z"]}
# PHASE_ON_COMP: dictionary defining which moveout we use to extract the waveform
PHASE_ON_COMP = {"N": "S", "1": "S", "E": "S", "2": "S", "Z": "P"}
# USE_APRIORI_PICKS: boolean. This option is IMPORTANT when running BPMF in HIGH SEISMICITY CONTEXTS, like
# during the aftershock sequence of a large earthquake. If there are many events happening
# close to each other in time, we need to guide PhaseNet to pick the right set of picks.
# For that, we use the predicted P- and S-wave times from backprojection to add extra weight to
# the picks closer to those times and make it more likely to identify them as the "best" picks.
# WARNING: If there are truly many events, even this trick might fail. It's because "phase association"
# is an intrinsically hard problem in this case, and the picking might be hard to do automatically.
USE_APRIORI_PICKS = True
#SEARCH_WIN_SEC: When `use_apriori_picks=True`, the P/S picks in the `DURATION_SEC`-long window are weighted
# using a gaussian centered on the predicted P/S wave arrivals and with standard deviation
# equal to `SEARCH_WIN_SEC`. Thus, the picks outside of +/- `3*SEARCH_WIN_SEC` are essentially
# given a weight of 0.
SEARCH_WIN_SEC = 1.0
# MAX_HORIZONTAL_UNC_KM: Horizontal location uncertainty, in km, above which we keep the template location
MAX_HORIZONTAL_UNC_KM = 10.
# location parameters
LOCATION_ROUTINE = "NLLoc"
# NLLOC_METHOD: string that defines what loss function is used by NLLoc, see http://alomax.free.fr/nlloc/ for more info.
# Using some flavor of 'EDT' is important to obtain robust locations that are not sensitive to pick outliers.
NLLOC_METHOD = "EDT_OT_WT_ML"
# MINIMUM_NUM_STATIONS_W_PICKS: minimum number of stations with picks to even try relocation.
MINIMUM_NUM_STATIONS_W_PICKS = 3
# we set a maximum tolerable difference, in percentage, between the picked time and the predicted travel time
MAX_TIME_DIFFERENT_PICKS_PREDICTED_PERCENT = 25
[13]:
def ml_picker(x, chunk_size=3000, device="cpu"):
"""ML-based seismic phase picker using PhaseNet.
For maximum flexibility, all interfacing with phase pickers is done through
wrapper functions like this one. This function must behave like:
`y = f(x)`,
where `y` are the time series of P- and S-wave probabilities. This function must
include all preprocessing steps that may be required, like chunking and normalization.
Parameters
----------
x : np.ndarray
Seismograms, shape (n_stations, n_channels=3, n_times).
chunk_size : int, optional
Size of the seismograms, in samples, used in the training of the ML model.
Default is 3000 (30 seconds at 100 Hz).
device : str, optional
Device to use to run the ML model, either "cpu" or "gpu". Default is
Returns
-------
ps_proba_time_series : np.ndarray
Time series of P- and S-wave probabilities, shape (n_stations, n_phases, n_times).
The first channel, `ps_proba_time_series[:, 0, :]` is the P-wave probability,
and the second, `ps_proba_time_series[:, 1, :]`, is the S-wave probability.
"""
from torch import no_grad, from_numpy
_ml_detector = sbm.PhaseNet.from_pretrained("original")
_ml_detector.eval()
if device == "gpu":
_ml_detector.to("cuda")
x = BPMF.utils.normalize_batch(x, normalization_window_sample=chunk_size)
with no_grad():
x = from_numpy(x).float().to("cuda" if device == "gpu" else "cpu")
ps_proba_time_series = _ml_detector(x)
# remove channel 0, which is probability of noise
return ps_proba_time_series[:, 1:, :].cpu().detach().numpy()
[14]:
events = {}
for i in tqdm(range(len(template_group.catalog.catalog)), desc="Relocating each individual event"):
row = template_group.catalog.catalog.iloc[i]
tid, evidx = row.name.split(".")
# get the template instance from template_group
template = template_group.templates[template_group.tindexes.loc[int(tid)]]
# this is the filename of the database where template tid's detected events were stored
detection_db_filename = f"detections_template{tid}.h5"
db_path = os.path.join(BPMF.cfg.OUTPUT_PATH, MATCHED_FILTER_DB)
with h5.File(os.path.join(db_path, detection_db_filename), mode="r") as fdet:
keys = list(fdet.keys())
event = BPMF.dataset.Event.read_from_file(
hdf5_file=fdet[keys[int(evidx)]], data_reader=data_reader_mseed
)
# set arrival_times attribute to re-pick P-/S-wave arrivals with prior information
event.set_arrival_times_from_moveouts(verbose=0)
# # attach data reader this way (note: conflict with data_reader argument in phasenet's wrapper module)
# event.data_reader = data_reader_mseed
# pick P-/S-wave arrivals
event.pick_PS_phases(
ml_picker,
DURATION_SEC,
threshold_P=THRESHOLD_P,
threshold_S=THRESHOLD_S,
component_aliases=COMPONENT_ALIASES,
data_folder=DATA_FOLDER,
upsampling=UPSAMPLING_BEFORE_PN_RELOCATION,
downsampling=DOWNSAMPLING_BEFORE_PN_RELOCATION,
use_apriori_picks=USE_APRIORI_PICKS,
keep_probability_time_series=True,
)
if len(event.picks.dropna(how="any")) >= MINIMUM_NUM_STATIONS_W_PICKS:
# first relocation, insensitive to outliers
event.relocate(
stations=net.stations, routine=LOCATION_ROUTINE, method=NLLOC_METHOD,
)
if "NLLoc_success" in event.aux_data:
# this variable was inserted into ev.aux_data if NLLoc successfully located the event
# use predicted times to remove outlier picks
event.remove_outlier_picks(max_diff_percent=MAX_TIME_DIFFERENT_PICKS_PREDICTED_PERCENT)
if len(event.picks.dropna(how="any")) >= MINIMUM_NUM_STATIONS_W_PICKS:
# first relocation, insensitive to outliers
event.relocate(
stations=net.stations, routine=LOCATION_ROUTINE, method=NLLOC_METHOD,
)
else:
del event.aux_data["NLLoc_success"]
events[row.name] = event
if ("NLLoc_success" in event.aux_data) and event.aux_data["NLLoc_success"] and (event.hmax_unc) < MAX_HORIZONTAL_UNC_KM:
pass
else:
# relocation was not successful, inherit location from template
tid = template_group.catalog.catalog.loc[row.name, "tid"]
event.inherit_location(template_group.templates[template_group.tindexes.loc[tid]])
template_group.catalog.catalog.loc[row.name, "longitude"] = event.longitude
template_group.catalog.catalog.loc[row.name, "latitude"] = event.latitude
template_group.catalog.catalog.loc[row.name, "depth"] = event.depth
template_group.catalog.catalog.loc[row.name, "origin_time"] = event.origin_time
template_group.catalog.catalog.loc[row.name, "hmax_unc"] = event.hmax_unc
template_group.catalog.catalog.loc[row.name, "hmin_unc"] = event.hmin_unc
template_group.catalog.catalog.loc[row.name, "vmax_unc"] = event.vmax_unc
template_group.catalog.catalog.loc[row.name, "az_hmax_unc"] = event.az_hmax_unc
Relocating each individual event: 0%| | 0/54 [00:00<?, ?it/s]/tmp/ipykernel_204257/1648401400.py:58: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '2012-07-26T00:58:11.040000Z' has dtype incompatible with datetime64[ms], please explicitly cast to a compatible dtype first.
template_group.catalog.catalog.loc[row.name, "origin_time"] = event.origin_time
Relocating each individual event: 100%|██████████| 54/54 [00:33<00:00, 1.61it/s]
[15]:
fig = template_group.catalog.plot_map(
figsize=(10, 10), network=net, s=50, markersize_station=50, lat_margin=0.02, plot_uncertainties=False
)
ax = fig.get_axes()[0]
ax.set_facecolor("dimgrey")
ax.patch.set_alpha(0.15)
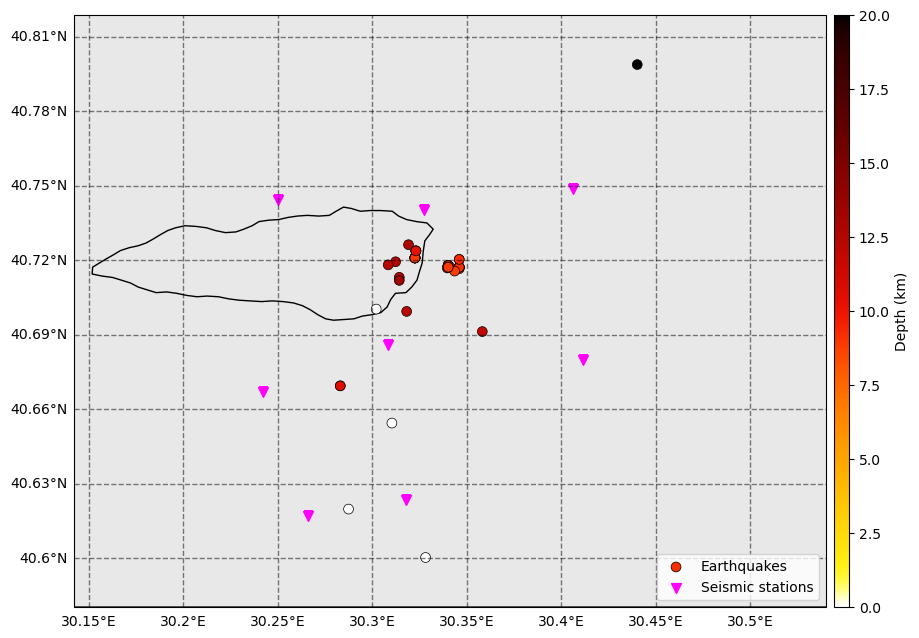
Assemble the backprojection and template matching catalog
When selecting the template events from the backprojection catalog, we imposed some quality criteria that might have thrown out some events that we still want in our final catalog. Here, we make a simple comparison of the backprojection and template matching catalogs to find these missing events and add them to the final catalog.
[16]:
BACKPROJECTION_CATALOG_FILENAME = "backprojection_catalog.csv"
[17]:
tm_catalog = template_group.catalog.catalog.copy()
tm_catalog.reset_index(inplace=True)
for i in range(len(tm_catalog)):
tm_catalog.loc[i, "event_id"] = f"tm_{tm_catalog.loc[i, 'event_id']}"
tm_catalog
[17]:
| event_id | longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | hmax_unc | hmin_unc | vmax_unc | az_hmax_unc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | tm_7.0 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:11.040000Z | 0.341836 | 7 | NaN | 1.343264e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 1 | tm_7.1 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:16.600000Z | 0.268420 | 7 | 5.56 | 1.343264e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 2 | tm_0.2 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:02:53.360000Z | 0.266884 | 0 | 276.76 | 1.343265e+09 | 0.00 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 3 | tm_0.3 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:03:47.000000Z | 0.404978 | 0 | 53.64 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 4 | tm_7.3 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:09:25.920000Z | 0.289663 | 7 | 338.96 | 1.343265e+09 | 338.92 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 5 | tm_0.5 | 30.320117 | 40.726875 | 12.300 | 2012-07-26T01:10:21.800000Z | 0.714110 | 0 | 56.28 | 1.343265e+09 | 0.16 | True | 1.810771 | 1.486301 | 2.841072 | 145.172409 |
| 6 | tm_7.5 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:10:43.920000Z | 0.590040 | 7 | 21.76 | 1.343265e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 7 | tm_0.7 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:12:32.960000Z | 0.317964 | 0 | 108.92 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 8 | tm_0.8 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:15:13.960000Z | 0.581384 | 0 | 161.88 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 9 | tm_0.9 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:15:14.080000Z | 0.332889 | 0 | 7.56 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 10 | tm_0.10 | 30.345508 | 40.716875 | 9.100 | 2012-07-26T01:15:54.200000Z | 0.286360 | 0 | 12.76 | 1.343265e+09 | 0.00 | True | 1.936473 | 1.198321 | 3.426819 | 84.525925 |
| 11 | tm_0.11 | 30.337695 | 40.716875 | 9.100 | 2012-07-26T01:15:54.280000Z | 1.000000 | 0 | 19.08 | 1.343265e+09 | 0.04 | True | 2.383360 | 1.332406 | 2.530699 | 87.887787 |
| 12 | tm_0.12 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:16:30.080000Z | 0.331540 | 0 | 35.84 | 1.343265e+09 | 0.00 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 13 | tm_0.13 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:18:32.960000Z | 0.257836 | 0 | 122.88 | 1.343266e+09 | 122.44 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 14 | tm_1.8 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T01:35:15.120000Z | 0.247586 | 1 | 1124.60 | 1.343267e+09 | 0.44 | True | 4.918229 | 2.903243 | 3.184359 | -135.746872 |
| 15 | tm_0.14 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:39:55.400000Z | 0.226896 | 0 | 1280.80 | 1.343267e+09 | 278.64 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 16 | tm_3.12 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T01:52:27.920000Z | 0.206768 | 3 | 2034.96 | 1.343268e+09 | 754.16 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 17 | tm_0.15 | 30.352344 | 40.677500 | 11.200 | 2012-07-26T01:52:36.760000Z | 0.392199 | 0 | 762.76 | 1.343268e+09 | 0.04 | True | 5.971222 | 2.580973 | 4.401469 | 104.680771 |
| 18 | tm_7.13 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T02:22:49.880000Z | 0.236185 | 7 | 1813.40 | 1.343269e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 19 | tm_0.17 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T02:24:36.320000Z | 0.468882 | 0 | 105.12 | 1.343269e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 20 | tm_1.11 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T02:35:01.560000Z | 1.000000 | 1 | 626.12 | 1.343270e+09 | 0.44 | True | 4.918229 | 2.903243 | 3.184359 | -135.746872 |
| 21 | tm_0.19 | 30.324023 | 40.714375 | 9.700 | 2012-07-26T03:00:39.000000Z | 0.513174 | 0 | 1537.84 | 1.343272e+09 | 0.00 | True | 1.869873 | 1.343959 | 3.491108 | 92.285568 |
| 22 | tm_3.18 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:08:33.640000Z | 0.411021 | 3 | 474.56 | 1.343272e+09 | 0.00 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 23 | tm_3.19 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:10:55.040000Z | 0.325226 | 3 | 141.52 | 1.343272e+09 | 141.48 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 24 | tm_3.20 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T04:30:33.520000Z | 0.190873 | 3 | 4778.48 | 1.343277e+09 | 4778.48 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 25 | tm_2.4 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:43:38.240000Z | 1.000000 | 2 | 5704.84 | 1.343278e+09 | 784.72 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 |
| 26 | tm_7.19 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T04:45:03.920000Z | 0.275260 | 7 | 5648.88 | 1.343278e+09 | 85.52 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 27 | tm_2.5 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:46:49.160000Z | 0.323422 | 2 | 190.92 | 1.343278e+09 | 104.80 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 |
| 28 | tm_2.6 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:48:38.520000Z | 0.355615 | 2 | 109.32 | 1.343278e+09 | 109.32 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 |
| 29 | tm_2.7 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:51:06.520000Z | 0.344914 | 2 | 148.04 | 1.343278e+09 | 147.88 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 |
| 30 | tm_3.24 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:22:04.440000Z | 0.284165 | 3 | 1857.76 | 1.343280e+09 | 1857.76 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 31 | tm_3.25 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:45:46.000000Z | 0.184268 | 3 | 1421.56 | 1.343282e+09 | 1421.56 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 32 | tm_3.26 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:46:59.240000Z | 0.267884 | 3 | 73.24 | 1.343282e+09 | 73.24 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 33 | tm_3.27 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:57:16.440000Z | 0.215643 | 3 | 617.20 | 1.343282e+09 | 617.20 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 34 | tm_3.28 | 30.295703 | 40.718750 | 11.800 | 2012-07-26T08:08:25.520000Z | 1.000000 | 3 | 7869.20 | 1.343290e+09 | 0.16 | True | 3.230978 | 2.065344 | 7.079447 | 85.408310 |
| 35 | tm_4.0 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:21:39.360000Z | 0.206163 | 4 | NaN | 1.343294e+09 | 4393.28 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 |
| 36 | tm_4.1 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:28:48.320000Z | 0.174172 | 4 | 428.96 | 1.343295e+09 | 428.96 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 |
| 37 | tm_4.2 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T10:07:23.680000Z | 1.000000 | 4 | 2315.36 | 1.343297e+09 | 2315.36 | True | 1.887676 | 1.122001 | 2.974967 | 90.954826 |
| 38 | tm_3.29 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:16:45.760000Z | 0.358623 | 3 | 7700.12 | 1.343298e+09 | 0.00 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 39 | tm_3.30 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:53:46.560000Z | 0.240390 | 3 | 2220.80 | 1.343300e+09 | 2220.80 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 40 | tm_3.31 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T11:02:23.560000Z | 0.350023 | 3 | 517.00 | 1.343301e+09 | 0.12 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 |
| 41 | tm_5.0 | 30.256641 | 40.631250 | 3.000 | 2012-07-26T11:55:35.400000Z | 1.000000 | 5 | NaN | 1.343304e+09 | 3192.04 | True | 3.262619 | 2.518279 | 3.942850 | 118.036263 |
| 42 | tm_6.0 | 30.297168 | 40.799687 | -1.950 | 2012-07-26T13:35:26.920000Z | 1.000000 | 6 | NaN | 1.343310e+09 | 5990.52 | True | 3.370789 | 1.351315 | 5.631534 | 89.182983 |
| 43 | tm_0.25 | 30.315234 | 40.721250 | 11.800 | 2012-07-26T13:48:32.480000Z | 0.643244 | 0 | 9969.16 | 1.343311e+09 | 0.04 | True | 1.674635 | 1.497335 | 2.909333 | -149.835159 |
| 44 | tm_0.26 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T13:50:18.560000Z | 0.324168 | 0 | 105.80 | 1.343311e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 |
| 45 | tm_7.24 | 30.314258 | 40.714375 | 12.900 | 2012-07-26T13:51:58.240000Z | 0.537169 | 7 | 100.08 | 1.343311e+09 | 0.00 | True | 1.987408 | 1.921854 | 5.325827 | 135.522507 |
| 46 | tm_0.28 | 30.314258 | 40.720625 | 11.700 | 2012-07-26T13:53:31.440000Z | 0.684881 | 0 | 93.04 | 1.343311e+09 | 0.04 | True | 1.651933 | 1.491066 | 3.102297 | 46.475956 |
| 47 | tm_7.26 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:54:54.160000Z | 0.408825 | 7 | 82.60 | 1.343311e+09 | 82.16 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 48 | tm_7.27 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:56:54.200000Z | 1.000000 | 7 | 120.04 | 1.343311e+09 | 119.60 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 |
| 49 | tm_2.13 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T14:38:50.440000Z | 0.240563 | 2 | 2718.96 | 1.343314e+09 | 2515.76 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 |
| 50 | tm_8.0 | 30.327686 | 40.600156 | -1.975 | 2012-07-26T15:06:19.960000Z | 1.000000 | 8 | NaN | 1.343315e+09 | 1649.60 | True | 1.060590 | 0.799781 | 0.697548 | 152.067474 |
| 51 | tm_4.3 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:26:52.520000Z | 0.251527 | 4 | 22768.84 | 1.343320e+09 | 4832.48 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 |
| 52 | tm_4.4 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:33:57.640000Z | 0.171122 | 4 | 425.12 | 1.343320e+09 | 425.12 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 |
| 53 | tm_9.0 | 30.408984 | 40.711250 | 5.800 | 2012-07-26T17:28:20.440000Z | 1.000000 | 9 | NaN | 1.343324e+09 | 3262.60 | True | 3.450314 | 1.634985 | 6.667332 | 72.088081 |
[18]:
bp_catalog = pd.read_csv(
os.path.join(BPMF.cfg.OUTPUT_PATH, BACKPROJECTION_CATALOG_FILENAME),
index_col=0
)
# convert origin times from string to pandas.Timestamp
bp_catalog["origin_time"] = pd.to_datetime(bp_catalog["origin_time"])
bp_catalog
[18]:
| longitude | latitude | depth | origin_time | hmax_unc | hmin_unc | az_hmax_unc | vmax_unc | event_id.1 | |
|---|---|---|---|---|---|---|---|---|---|
| event_id | |||||||||
| 2012-07-26T01:10:21.800000Z | 30.318164 | 40.728125 | 12.300 | 2012-07-26 01:10:21.800 | 1.815502 | 1.442653 | 158.022300 | 2.784858 | bp_0 |
| 2012-07-26T01:15:54.240000Z | 30.337695 | 40.718125 | 9.300 | 2012-07-26 01:15:54.240 | 2.364013 | 1.180201 | 91.700750 | 2.169170 | bp_1 |
| 2012-07-26T02:35:01.600000Z | 30.284961 | 40.670625 | 10.900 | 2012-07-26 02:35:01.600 | 4.918229 | 2.903243 | 44.253128 | 3.184359 | bp_2 |
| 2012-07-26T03:00:39.000000Z | 30.324023 | 40.714375 | 9.700 | 2012-07-26 03:00:39.000 | 1.879501 | 1.345109 | 94.391914 | 3.404398 | bp_3 |
| 2012-07-26T04:43:38.240000Z | 30.323047 | 40.723750 | 10.600 | 2012-07-26 04:43:38.240 | 6.366376 | 2.900089 | 120.716190 | 5.315764 | bp_4 |
| 2012-07-26T08:08:25.640000Z | 30.324023 | 40.723125 | 9.500 | 2012-07-26 08:08:25.640 | 1.911768 | 1.290201 | 114.386940 | 3.009666 | bp_5 |
| 2012-07-26T10:07:23.680000Z | 30.341602 | 40.716875 | 8.900 | 2012-07-26 10:07:23.680 | 1.846672 | 1.090383 | 90.523130 | 2.885354 | bp_6 |
| 2012-07-26T11:55:35.640000Z | 30.256641 | 40.631250 | 3.000 | 2012-07-26 11:55:35.640 | 3.262619 | 2.518279 | 118.036260 | 3.942850 | bp_7 |
| 2012-07-26T13:35:26.160000Z | 30.297168 | 40.799687 | -1.950 | 2012-07-26 13:35:26.160 | 3.370789 | 1.351314 | 89.182980 | 5.631534 | bp_8 |
| 2012-07-26T13:48:32.440000Z | 30.314258 | 40.721875 | 11.900 | 2012-07-26 13:48:32.440 | 1.578049 | 1.465162 | 56.293896 | 2.946252 | bp_9 |
| 2012-07-26T13:51:58.240000Z | 30.314258 | 40.711875 | 13.100 | 2012-07-26 13:51:58.240 | 1.727335 | 1.487784 | 5.879410 | 3.505660 | bp_10 |
| 2012-07-26T13:53:31.440000Z | 30.316211 | 40.723125 | 11.300 | 2012-07-26 13:53:31.440 | 1.587689 | 1.547229 | 10.778519 | 2.993630 | bp_11 |
| 2012-07-26T13:56:54.240000Z | 30.343555 | 40.716875 | 9.100 | 2012-07-26 13:56:54.240 | 2.342871 | 1.103207 | 83.570360 | 3.933246 | bp_12 |
| 2012-07-26T15:06:20.040000Z | 30.326709 | 40.600156 | -1.975 | 2012-07-26 15:06:20.040 | 1.255288 | 0.642705 | 95.437990 | 0.831612 | bp_13 |
| 2012-07-26T17:28:20.240000Z | 30.408984 | 40.711250 | 5.800 | 2012-07-26 17:28:20.240 | 3.450314 | 1.634985 | 72.088080 | 6.667332 | bp_14 |
[19]:
# catalog merging parameters
dt_criterion_pd = pd.Timedelta(DT_CRITERION_SEC, "s")
HMAX_UNC_CRITERION_KM = 10.
[20]:
combined_catalog = tm_catalog.copy()
missing_event = np.zeros(len(bp_catalog), dtype=bool)
for i in tqdm(range(len(bp_catalog)), desc="Loop through BP cat"):
if bp_catalog.iloc[i]["hmax_unc"] > HMAX_UNC_CRITERION_KM:
continue
t_min = bp_catalog.iloc[i]["origin_time"] - dt_criterion_pd
t_max = bp_catalog.iloc[i]["origin_time"] + dt_criterion_pd
subset_tm = (tm_catalog["origin_time"] > t_min) & (tm_catalog["origin_time"] < t_max)
if np.sum(subset_tm) == 0:
missing_event[i] = True
combined_catalog = pd.concat(
(tm_catalog, bp_catalog[missing_event]),
ignore_index=True
)
combined_catalog.sort_values(
"origin_time", ascending=True, inplace=True
)
Loop through BP cat: 100%|██████████| 15/15 [00:00<00:00, 750.59it/s]
/tmp/ipykernel_204257/2661912240.py:13: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
combined_catalog = pd.concat(
And here is the combined catalog! In this simple example, it appears that all events in the backprojection catalog were re-detected in the template matching catalog so that the final catalog has no extra events with respect to the template matching catalog. However, it may not be always like that. Some events in the backprojection catalog may not have been well enough located for you to use them as templates, and they may not have been subsequently re-detected in the template matching catalog.
[21]:
combined_catalog
[21]:
| event_id | longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | hmax_unc | hmin_unc | vmax_unc | az_hmax_unc | event_id.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | tm_7.0 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:11.040000Z | 0.341836 | 7.0 | NaN | 1.343264e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 1 | tm_7.1 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:16.600000Z | 0.268420 | 7.0 | 5.56 | 1.343264e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 2 | tm_0.2 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:02:53.360000Z | 0.266884 | 0.0 | 276.76 | 1.343265e+09 | 0.00 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 3 | tm_0.3 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:03:47.000000Z | 0.404978 | 0.0 | 53.64 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 4 | tm_7.3 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:09:25.920000Z | 0.289663 | 7.0 | 338.96 | 1.343265e+09 | 338.92 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 5 | tm_0.5 | 30.320117 | 40.726875 | 12.300 | 2012-07-26T01:10:21.800000Z | 0.714110 | 0.0 | 56.28 | 1.343265e+09 | 0.16 | True | 1.810771 | 1.486301 | 2.841072 | 145.172409 | NaN |
| 6 | tm_7.5 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:10:43.920000Z | 0.590040 | 7.0 | 21.76 | 1.343265e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 7 | tm_0.7 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:12:32.960000Z | 0.317964 | 0.0 | 108.92 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 8 | tm_0.8 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:15:13.960000Z | 0.581384 | 0.0 | 161.88 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 9 | tm_0.9 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:15:14.080000Z | 0.332889 | 0.0 | 7.56 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 10 | tm_0.10 | 30.345508 | 40.716875 | 9.100 | 2012-07-26T01:15:54.200000Z | 0.286360 | 0.0 | 12.76 | 1.343265e+09 | 0.00 | True | 1.936473 | 1.198321 | 3.426819 | 84.525925 | NaN |
| 11 | tm_0.11 | 30.337695 | 40.716875 | 9.100 | 2012-07-26T01:15:54.280000Z | 1.000000 | 0.0 | 19.08 | 1.343265e+09 | 0.04 | True | 2.383360 | 1.332406 | 2.530699 | 87.887787 | NaN |
| 12 | tm_0.12 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:16:30.080000Z | 0.331540 | 0.0 | 35.84 | 1.343265e+09 | 0.00 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 13 | tm_0.13 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:18:32.960000Z | 0.257836 | 0.0 | 122.88 | 1.343266e+09 | 122.44 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 14 | tm_1.8 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T01:35:15.120000Z | 0.247586 | 1.0 | 1124.60 | 1.343267e+09 | 0.44 | True | 4.918229 | 2.903243 | 3.184359 | -135.746872 | NaN |
| 15 | tm_0.14 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:39:55.400000Z | 0.226896 | 0.0 | 1280.80 | 1.343267e+09 | 278.64 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 16 | tm_3.12 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T01:52:27.920000Z | 0.206768 | 3.0 | 2034.96 | 1.343268e+09 | 754.16 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 17 | tm_0.15 | 30.352344 | 40.677500 | 11.200 | 2012-07-26T01:52:36.760000Z | 0.392199 | 0.0 | 762.76 | 1.343268e+09 | 0.04 | True | 5.971222 | 2.580973 | 4.401469 | 104.680771 | NaN |
| 18 | tm_7.13 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T02:22:49.880000Z | 0.236185 | 7.0 | 1813.40 | 1.343269e+09 | 0.00 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 19 | tm_0.17 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T02:24:36.320000Z | 0.468882 | 0.0 | 105.12 | 1.343269e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 20 | tm_1.11 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T02:35:01.560000Z | 1.000000 | 1.0 | 626.12 | 1.343270e+09 | 0.44 | True | 4.918229 | 2.903243 | 3.184359 | -135.746872 | NaN |
| 21 | tm_0.19 | 30.324023 | 40.714375 | 9.700 | 2012-07-26T03:00:39.000000Z | 0.513174 | 0.0 | 1537.84 | 1.343272e+09 | 0.00 | True | 1.869873 | 1.343959 | 3.491108 | 92.285568 | NaN |
| 22 | tm_3.18 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:08:33.640000Z | 0.411021 | 3.0 | 474.56 | 1.343272e+09 | 0.00 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 23 | tm_3.19 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:10:55.040000Z | 0.325226 | 3.0 | 141.52 | 1.343272e+09 | 141.48 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 24 | tm_3.20 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T04:30:33.520000Z | 0.190873 | 3.0 | 4778.48 | 1.343277e+09 | 4778.48 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 25 | tm_2.4 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:43:38.240000Z | 1.000000 | 2.0 | 5704.84 | 1.343278e+09 | 784.72 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| 26 | tm_7.19 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T04:45:03.920000Z | 0.275260 | 7.0 | 5648.88 | 1.343278e+09 | 85.52 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 27 | tm_2.5 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:46:49.160000Z | 0.323422 | 2.0 | 190.92 | 1.343278e+09 | 104.80 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| 28 | tm_2.6 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:48:38.520000Z | 0.355615 | 2.0 | 109.32 | 1.343278e+09 | 109.32 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| 29 | tm_2.7 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:51:06.520000Z | 0.344914 | 2.0 | 148.04 | 1.343278e+09 | 147.88 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| 30 | tm_3.24 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:22:04.440000Z | 0.284165 | 3.0 | 1857.76 | 1.343280e+09 | 1857.76 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 31 | tm_3.25 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:45:46.000000Z | 0.184268 | 3.0 | 1421.56 | 1.343282e+09 | 1421.56 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 32 | tm_3.26 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:46:59.240000Z | 0.267884 | 3.0 | 73.24 | 1.343282e+09 | 73.24 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 33 | tm_3.27 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:57:16.440000Z | 0.215643 | 3.0 | 617.20 | 1.343282e+09 | 617.20 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 34 | tm_3.28 | 30.295703 | 40.718750 | 11.800 | 2012-07-26T08:08:25.520000Z | 1.000000 | 3.0 | 7869.20 | 1.343290e+09 | 0.16 | True | 3.230978 | 2.065344 | 7.079447 | 85.408310 | NaN |
| 35 | tm_4.0 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:21:39.360000Z | 0.206163 | 4.0 | NaN | 1.343294e+09 | 4393.28 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| 36 | tm_4.1 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:28:48.320000Z | 0.174172 | 4.0 | 428.96 | 1.343295e+09 | 428.96 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| 37 | tm_4.2 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T10:07:23.680000Z | 1.000000 | 4.0 | 2315.36 | 1.343297e+09 | 2315.36 | True | 1.887676 | 1.122001 | 2.974967 | 90.954826 | NaN |
| 38 | tm_3.29 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:16:45.760000Z | 0.358623 | 3.0 | 7700.12 | 1.343298e+09 | 0.00 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 39 | tm_3.30 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:53:46.560000Z | 0.240390 | 3.0 | 2220.80 | 1.343300e+09 | 2220.80 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 40 | tm_3.31 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T11:02:23.560000Z | 0.350023 | 3.0 | 517.00 | 1.343301e+09 | 0.12 | True | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| 41 | tm_5.0 | 30.256641 | 40.631250 | 3.000 | 2012-07-26T11:55:35.400000Z | 1.000000 | 5.0 | NaN | 1.343304e+09 | 3192.04 | True | 3.262619 | 2.518279 | 3.942850 | 118.036263 | NaN |
| 42 | tm_6.0 | 30.297168 | 40.799687 | -1.950 | 2012-07-26T13:35:26.920000Z | 1.000000 | 6.0 | NaN | 1.343310e+09 | 5990.52 | True | 3.370789 | 1.351315 | 5.631534 | 89.182983 | NaN |
| 43 | tm_0.25 | 30.315234 | 40.721250 | 11.800 | 2012-07-26T13:48:32.480000Z | 0.643244 | 0.0 | 9969.16 | 1.343311e+09 | 0.04 | True | 1.674635 | 1.497335 | 2.909333 | -149.835159 | NaN |
| 44 | tm_0.26 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T13:50:18.560000Z | 0.324168 | 0.0 | 105.80 | 1.343311e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| 45 | tm_7.24 | 30.314258 | 40.714375 | 12.900 | 2012-07-26T13:51:58.240000Z | 0.537169 | 7.0 | 100.08 | 1.343311e+09 | 0.00 | True | 1.987408 | 1.921854 | 5.325827 | 135.522507 | NaN |
| 46 | tm_0.28 | 30.314258 | 40.720625 | 11.700 | 2012-07-26T13:53:31.440000Z | 0.684881 | 0.0 | 93.04 | 1.343311e+09 | 0.04 | True | 1.651933 | 1.491066 | 3.102297 | 46.475956 | NaN |
| 47 | tm_7.26 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:54:54.160000Z | 0.408825 | 7.0 | 82.60 | 1.343311e+09 | 82.16 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 48 | tm_7.27 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:56:54.200000Z | 1.000000 | 7.0 | 120.04 | 1.343311e+09 | 119.60 | True | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| 49 | tm_2.13 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T14:38:50.440000Z | 0.240563 | 2.0 | 2718.96 | 1.343314e+09 | 2515.76 | True | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| 50 | tm_8.0 | 30.327686 | 40.600156 | -1.975 | 2012-07-26T15:06:19.960000Z | 1.000000 | 8.0 | NaN | 1.343315e+09 | 1649.60 | True | 1.060590 | 0.799781 | 0.697548 | 152.067474 | NaN |
| 51 | tm_4.3 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:26:52.520000Z | 0.251527 | 4.0 | 22768.84 | 1.343320e+09 | 4832.48 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| 52 | tm_4.4 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:33:57.640000Z | 0.171122 | 4.0 | 425.12 | 1.343320e+09 | 425.12 | True | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| 53 | tm_9.0 | 30.408984 | 40.711250 | 5.800 | 2012-07-26T17:28:20.440000Z | 1.000000 | 9.0 | NaN | 1.343324e+09 | 3262.60 | True | 3.450314 | 1.634985 | 6.667332 | 72.088081 | NaN |
In this example, we see that two entries of the catalog end up pointing to the same event (see below):
[22]:
combined_catalog[
(combined_catalog["origin_time"] >= pd.Timestamp("2012-07-26T01:15:00"))
&
(combined_catalog["origin_time"] <= pd.Timestamp("2012-07-26T01:15:30"))
]
[22]:
| event_id | longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | hmax_unc | hmin_unc | vmax_unc | az_hmax_unc | event_id.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | tm_0.8 | 30.337695 | 40.718125 | 9.3 | 2012-07-26T01:15:13.960000Z | 0.581384 | 0.0 | 161.88 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.16917 | 91.700752 | NaN |
| 9 | tm_0.9 | 30.337695 | 40.718125 | 9.3 | 2012-07-26T01:15:14.080000Z | 0.332889 | 0.0 | 7.56 | 1.343265e+09 | 0.04 | True | 2.364013 | 1.180201 | 2.16917 | 91.700752 | NaN |
versus (before relocating each event individually)
[23]:
initial_catalog[
(initial_catalog["origin_time"] >= pd.Timestamp("2012-07-26T01:15:00"))
&
(initial_catalog["origin_time"] <= pd.Timestamp("2012-07-26T01:15:30"))
]
[23]:
| longitude | latitude | depth | origin_time | cc | tid | return_time | origin_time_sec | interevent_time_sec | unique_event | |
|---|---|---|---|---|---|---|---|---|---|---|
| event_id | ||||||||||
| 0.8 | 30.337695 | 40.718125 | 9.3 | 2012-07-26 01:15:14.840 | 0.581384 | 0 | 161.88 | 1.343265e+09 | 0.04 | True |
| 0.9 | 30.337695 | 40.718125 | 9.3 | 2012-07-26 01:15:22.400 | 0.332889 | 0 | 7.56 | 1.343265e+09 | 0.04 | True |
This is because, despite using the use_apriori_picks=True, the automatic picking ended up picking the event before tm_0.9. So, before I release a fix to this issue, we need to clean up these redundant catalog entries! And keep in mind that the initial template matching catalog might have better temporal resolution.
Last clean up
[24]:
final_cat = combined_catalog.copy()
final_cat["origin_time_sec"] = (
final_cat["origin_time"].values.astype("datetime64[ms]").astype("float64") / 1000.
)
num_removed = -1
iteration = 0
while num_removed != 0:
print(f"------ Iteration {iteration} --------")
interevent_time_sec = (
final_cat["origin_time_sec"].values[1:] - final_cat["origin_time_sec"].values[:-1]
)
interevent_time_sec = np.hstack( (1000., interevent_time_sec) )
remove = np.zeros(len(final_cat), dtype=bool)
for i in np.where(interevent_time_sec < DT_CRITERION_SEC)[0]:
dist = BPMF.utils.two_point_epicentral_distance(
final_cat.iloc[i-1].longitude,
final_cat.iloc[i-1].latitude,
final_cat.iloc[i].longitude,
final_cat.iloc[i].latitude,
)
if dist < DISTANCE_CRITERION_KM:
if final_cat.iloc[i-1].hmax_unc < final_cat.iloc[i].hmax_unc:
remove[i] = True
else:
remove[i-1] = True
num_removed = np.sum(remove)
print(f"Removed {num_removed} events. Examples:")
if num_removed > 1:
removed_events = np.where(remove)[0]
print(final_cat[["origin_time", "event_id", "longitude", "latitude"]].iloc[removed_events[0]])
if interevent_time_sec[removed_events[0]] < DT_CRITERION_SEC:
print(final_cat[["origin_time", "event_id", "longitude",
"latitude"]].iloc[removed_events[0] - 1])
else:
print(final_cat[["origin_time", "event_id", "longitude",
"latitude"]].iloc[removed_events[0] + 1])
final_cat = final_cat[~remove]
iteration += 1
------ Iteration 0 --------
Removed 2 events. Examples:
origin_time 2012-07-26T01:15:13.960000Z
event_id tm_0.8
longitude 30.337695
latitude 40.718125
Name: 8, dtype: object
origin_time 2012-07-26T01:15:14.080000Z
event_id tm_0.9
longitude 30.337695
latitude 40.718125
Name: 9, dtype: object
------ Iteration 1 --------
Removed 0 events. Examples:
[25]:
final_cat.set_index("event_id", drop=False, inplace=True)
final_cat.drop(columns=["interevent_time_sec", "unique_event", "origin_time_sec"], inplace=True)
final_cat.sort_values("origin_time", ascending=True, inplace=True)
final_cat
[25]:
| event_id | longitude | latitude | depth | origin_time | cc | tid | return_time | hmax_unc | hmin_unc | vmax_unc | az_hmax_unc | event_id.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| event_id | |||||||||||||
| tm_7.0 | tm_7.0 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:11.040000Z | 0.341836 | 7.0 | NaN | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_7.1 | tm_7.1 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T00:58:16.600000Z | 0.268420 | 7.0 | 5.56 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_0.2 | tm_0.2 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:02:53.360000Z | 0.266884 | 0.0 | 276.76 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_0.3 | tm_0.3 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:03:47.000000Z | 0.404978 | 0.0 | 53.64 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_7.3 | tm_7.3 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:09:25.920000Z | 0.289663 | 7.0 | 338.96 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_0.5 | tm_0.5 | 30.320117 | 40.726875 | 12.300 | 2012-07-26T01:10:21.800000Z | 0.714110 | 0.0 | 56.28 | 1.810771 | 1.486301 | 2.841072 | 145.172409 | NaN |
| tm_7.5 | tm_7.5 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T01:10:43.920000Z | 0.590040 | 7.0 | 21.76 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_0.7 | tm_0.7 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:12:32.960000Z | 0.317964 | 0.0 | 108.92 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_0.9 | tm_0.9 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:15:14.080000Z | 0.332889 | 0.0 | 7.56 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_0.10 | tm_0.10 | 30.345508 | 40.716875 | 9.100 | 2012-07-26T01:15:54.200000Z | 0.286360 | 0.0 | 12.76 | 1.936473 | 1.198321 | 3.426819 | 84.525925 | NaN |
| tm_0.12 | tm_0.12 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:16:30.080000Z | 0.331540 | 0.0 | 35.84 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_0.13 | tm_0.13 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:18:32.960000Z | 0.257836 | 0.0 | 122.88 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_1.8 | tm_1.8 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T01:35:15.120000Z | 0.247586 | 1.0 | 1124.60 | 4.918229 | 2.903243 | 3.184359 | -135.746872 | NaN |
| tm_0.14 | tm_0.14 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T01:39:55.400000Z | 0.226896 | 0.0 | 1280.80 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_3.12 | tm_3.12 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T01:52:27.920000Z | 0.206768 | 3.0 | 2034.96 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_0.15 | tm_0.15 | 30.352344 | 40.677500 | 11.200 | 2012-07-26T01:52:36.760000Z | 0.392199 | 0.0 | 762.76 | 5.971222 | 2.580973 | 4.401469 | 104.680771 | NaN |
| tm_7.13 | tm_7.13 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T02:22:49.880000Z | 0.236185 | 7.0 | 1813.40 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_0.17 | tm_0.17 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T02:24:36.320000Z | 0.468882 | 0.0 | 105.12 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_1.11 | tm_1.11 | 30.284961 | 40.670625 | 10.900 | 2012-07-26T02:35:01.560000Z | 1.000000 | 1.0 | 626.12 | 4.918229 | 2.903243 | 3.184359 | -135.746872 | NaN |
| tm_0.19 | tm_0.19 | 30.324023 | 40.714375 | 9.700 | 2012-07-26T03:00:39.000000Z | 0.513174 | 0.0 | 1537.84 | 1.869873 | 1.343959 | 3.491108 | 92.285568 | NaN |
| tm_3.18 | tm_3.18 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:08:33.640000Z | 0.411021 | 3.0 | 474.56 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.19 | tm_3.19 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T03:10:55.040000Z | 0.325226 | 3.0 | 141.52 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.20 | tm_3.20 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T04:30:33.520000Z | 0.190873 | 3.0 | 4778.48 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_2.4 | tm_2.4 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:43:38.240000Z | 1.000000 | 2.0 | 5704.84 | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| tm_7.19 | tm_7.19 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T04:45:03.920000Z | 0.275260 | 7.0 | 5648.88 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_2.5 | tm_2.5 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:46:49.160000Z | 0.323422 | 2.0 | 190.92 | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| tm_2.6 | tm_2.6 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:48:38.520000Z | 0.355615 | 2.0 | 109.32 | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| tm_2.7 | tm_2.7 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T04:51:06.520000Z | 0.344914 | 2.0 | 148.04 | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| tm_3.24 | tm_3.24 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:22:04.440000Z | 0.284165 | 3.0 | 1857.76 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.25 | tm_3.25 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:45:46.000000Z | 0.184268 | 3.0 | 1421.56 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.26 | tm_3.26 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:46:59.240000Z | 0.267884 | 3.0 | 73.24 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.27 | tm_3.27 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T05:57:16.440000Z | 0.215643 | 3.0 | 617.20 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.28 | tm_3.28 | 30.295703 | 40.718750 | 11.800 | 2012-07-26T08:08:25.520000Z | 1.000000 | 3.0 | 7869.20 | 3.230978 | 2.065344 | 7.079447 | 85.408310 | NaN |
| tm_4.0 | tm_4.0 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:21:39.360000Z | 0.206163 | 4.0 | NaN | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| tm_4.1 | tm_4.1 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T09:28:48.320000Z | 0.174172 | 4.0 | 428.96 | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| tm_4.2 | tm_4.2 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T10:07:23.680000Z | 1.000000 | 4.0 | 2315.36 | 1.887676 | 1.122001 | 2.974967 | 90.954826 | NaN |
| tm_3.29 | tm_3.29 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:16:45.760000Z | 0.358623 | 3.0 | 7700.12 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.30 | tm_3.30 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T10:53:46.560000Z | 0.240390 | 3.0 | 2220.80 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_3.31 | tm_3.31 | 30.324023 | 40.723125 | 9.500 | 2012-07-26T11:02:23.560000Z | 0.350023 | 3.0 | 517.00 | 1.911768 | 1.290201 | 3.009666 | 114.386940 | NaN |
| tm_5.0 | tm_5.0 | 30.256641 | 40.631250 | 3.000 | 2012-07-26T11:55:35.400000Z | 1.000000 | 5.0 | NaN | 3.262619 | 2.518279 | 3.942850 | 118.036263 | NaN |
| tm_6.0 | tm_6.0 | 30.297168 | 40.799687 | -1.950 | 2012-07-26T13:35:26.920000Z | 1.000000 | 6.0 | NaN | 3.370789 | 1.351315 | 5.631534 | 89.182983 | NaN |
| tm_0.25 | tm_0.25 | 30.315234 | 40.721250 | 11.800 | 2012-07-26T13:48:32.480000Z | 0.643244 | 0.0 | 9969.16 | 1.674635 | 1.497335 | 2.909333 | -149.835159 | NaN |
| tm_0.26 | tm_0.26 | 30.337695 | 40.718125 | 9.300 | 2012-07-26T13:50:18.560000Z | 0.324168 | 0.0 | 105.80 | 2.364013 | 1.180201 | 2.169170 | 91.700752 | NaN |
| tm_7.24 | tm_7.24 | 30.314258 | 40.714375 | 12.900 | 2012-07-26T13:51:58.240000Z | 0.537169 | 7.0 | 100.08 | 1.987408 | 1.921854 | 5.325827 | 135.522507 | NaN |
| tm_0.28 | tm_0.28 | 30.314258 | 40.720625 | 11.700 | 2012-07-26T13:53:31.440000Z | 0.684881 | 0.0 | 93.04 | 1.651933 | 1.491066 | 3.102297 | 46.475956 | NaN |
| tm_7.26 | tm_7.26 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:54:54.160000Z | 0.408825 | 7.0 | 82.60 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_7.27 | tm_7.27 | 30.343555 | 40.716875 | 9.100 | 2012-07-26T13:56:54.200000Z | 1.000000 | 7.0 | 120.04 | 2.342871 | 1.103207 | 3.933246 | 83.570358 | NaN |
| tm_2.13 | tm_2.13 | 30.323047 | 40.723750 | 10.600 | 2012-07-26T14:38:50.440000Z | 0.240563 | 2.0 | 2718.96 | 6.366376 | 2.900089 | 5.315764 | 120.716187 | NaN |
| tm_8.0 | tm_8.0 | 30.327686 | 40.600156 | -1.975 | 2012-07-26T15:06:19.960000Z | 1.000000 | 8.0 | NaN | 1.060590 | 0.799781 | 0.697548 | 152.067474 | NaN |
| tm_4.3 | tm_4.3 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:26:52.520000Z | 0.251527 | 4.0 | 22768.84 | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| tm_4.4 | tm_4.4 | 30.341602 | 40.716875 | 8.900 | 2012-07-26T16:33:57.640000Z | 0.171122 | 4.0 | 425.12 | 1.846672 | 1.090383 | 2.885354 | 90.523132 | NaN |
| tm_9.0 | tm_9.0 | 30.408984 | 40.711250 | 5.800 | 2012-07-26T17:28:20.440000Z | 1.000000 | 9.0 | NaN | 3.450314 | 1.634985 | 6.667332 | 72.088081 | NaN |
Save final catalog
[26]:
# csv format
final_cat.to_csv(
os.path.join(BPMF.cfg.OUTPUT_PATH, OUTPUT_CSV_FILENAME)
)
[27]:
# hdf5 / BPMF format
for i in range(len(final_cat)):
evid = final_cat.iloc[i]["event_id"]
if evid[:2] == "tm":
events[evid.split("_")[1]].write(
OUTPUT_DB_FILENAME,
db_path=BPMF.cfg.OUTPUT_PATH,
gid=evid
)
elif evid[:2] == "bp":
with h5.File(os.path.join(BPMF.cfg.OUTPUT_PATH, OUTPUT_DB_FILENAME), mode="a") as fout:
with h5.File(os.path.join(BPMF.cfg.OUTPUT_PATH, BACKPROJ_DB_FILENAME), mode="r") as fin:
# copy the corresponding hdf5 group into fout
fin.copy(fin[evid], fout)
[28]:
# The final cat!
BPMF.utils.donefun()
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⡤⣤⣀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⡀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢀⡏⠀⠀⠈⠳⣄⠀⠀⠀⠀⠀⣀⠴⠋⠉⠉⡆⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢸⠀⠀⠀⠀⠀⠈⠉⠉⠙⠓⠚⠁⠀⠀⠀⠀⣿⠀⠀⠀⠀⠀
⠀⠀⠀⠀⢀⠞⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠹⣄⠀⠀⠀⠀
⠀⠀⠀⠀⡞⠀⠀⠀⠀⠀⠶⠀⠀⠀⠀⠀⠀⠦⠀⠀⠀⠀⠀⠸⡆⠀⠀⠀
⢠⣤⣶⣾⣧⣤⣤⣀⡀⠀⠀⠀⠀⠈⠀⠀⠀⢀⡤⠴⠶⠤⢤⡀⣧⣀⣀⠀
⠻⠶⣾⠁⠀⠀⠀⠀⠙⣆⠀⠀⠀⠀⠀⠀⣰⠋⠀⠀⠀⠀⠀⢹⣿⣭⣽⠇
⠀⠀⠙⠤⠴⢤⡤⠤⠤⠋⠉⠉⠉⠉⠉⠉⠉⠳⠖⠦⠤⠶⠦⠞⠁⠀⠀⠀
⠀ALL DONE!⠀⠀⠀