Build Template Database
In this notebook, we use the events detected in notebook 5, and further characterized in notebooks 6 ands 7, to build a database of template events. This step consists mostly in building data and metadata files but also allows the selection of events based on quality and the grouping of similar events. We want to avoid having too many similar templates in the database as it means useless, redundant computation in the template matching process (similar templates detect the same events).
[1]:
import os
from multiprocessing import cpu_count
n_CPUs = max(cpu_count(), 24)
os.environ["OMP_NUM_THREADS"] = str(n_CPUs)
import BPMF
import h5py as h5
import matplotlib.pyplot as plt
import numpy as np
from time import time as give_time
from tqdm import tqdm
from BPMF.data_reader_examples import data_reader_mseed
Error. nthreads cannot be larger than environment variable "NUMEXPR_MAX_THREADS" (64)
[2]:
# %config InlineBackend.figure_formats = ["svg"]
[3]:
# program parameters
DB_FILENAME = "reloc_bp.h5"
DB_PATH_T = "template_db"
DATA_FOLDER = "preprocessed_2_12"
NETWORK_FILENAME = "network.csv"
[4]:
# read network metadata
net = BPMF.dataset.Network(NETWORK_FILENAME)
net.read()
Read the database of detected events
We read the database of events detected with backprojection and, with them, create BPMF.dataset.Template instances.
[5]:
# HMAX_LOCATION_UNCERTAINTY_KM: All events with hmax_unc < HMAX_LOCATION_UNCERTAINTY_KM will be selected
# as candidate template events
HMAX_LOCATION_UNCERTAINTY_KM = 5.0
# NOISE_WINDOW_FOR_SNR_SEC: Duration, in seconds, of the window taken before the event's origin time
NOISE_WINDOW_FOR_SNR_SEC = 5.0
[6]:
templates = []
tid = 0
with h5.File(os.path.join(BPMF.cfg.OUTPUT_PATH, DB_FILENAME), mode="r") as f:
print(f"Checking {DB_FILENAME}...")
for key in tqdm(f.keys()):
event = BPMF.dataset.Event.read_from_file(
DB_FILENAME, db_path=BPMF.cfg.OUTPUT_PATH, gid=key
)
event.sampling_rate = BPMF.cfg.SAMPLING_RATE_HZ # necessary if backprojection and template matching at not done at the same sampling rate
if ("NLLoc_success" in event.aux_data) and event.aux_data["NLLoc_success"]:
if event.hmax_unc < HMAX_LOCATION_UNCERTAINTY_KM:
# if event was well relocated with NLLoc, use its location
event.set_moveouts_to_theoretical_times()
else:
# only use the best located events as templates
continue
event.where = os.path.join(
BPMF.cfg.INPUT_PATH,
str(event.origin_time.year),
event.origin_time.strftime("%Y%m%d"),
)
event.read_waveforms(
BPMF.cfg.TEMPLATE_LEN_SEC,
data_folder=DATA_FOLDER,
data_reader=data_reader_mseed,
n_threads=4
)
# computing the signal-to-noise ratio here may add a lot of
# computation time if you're scanning through a lot of events,
# but it greatly helps with choosing the best stations for
# template matching, in the following
event.set_availability()
event.compute_snr(
noise_window=NOISE_WINDOW_FOR_SNR_SEC,
data_folder=DATA_FOLDER,
data_reader=data_reader_mseed,
)
template = BPMF.dataset.Template.init_from_event(event)
template.id = tid
template.set_aux_data({"tid": tid})
templates.append(template)
tid += 1
Checking reloc_bp.h5...
100%|██████████| 15/15 [00:05<00:00, 2.72it/s]
Remove redundant templates
We first create an BPMF.dataset.TemplateGroup instance with the templates built in the previous cell. This class offers a number of methods to operate on groups of templates.
[7]:
template_group = BPMF.dataset.TemplateGroup(templates, net)
# this trick is necessary to make the class aware that the waveforms are already
# attached to the Template instances (_update_attributes should never be called at
# any other time of the workflow).
template_group._update_attributes.append("read_waveforms")
# normalize the waveforms
template_group.normalize()
[8]:
# parameters controlling how the inter-template correlation matrix is computed
DISTANCE_THRESHOLD_KM = 5. # in km, criterion on ellipsoid separation
N_CLOSEST_STATIONS = 10 # > larger than total number of stations, i.e. use all stations
MAX_LAG_SAMP = 5 # in samples, maximum time shift allowed when searching for similarity
TemplateGroup.compute_intertemplate_cc computes the network-averaged correlation coefficient between templates. To account for possible location errors – and, therefore, different alignments on the P- and S-wave arrivals – we search for the maximum correlation within +/- MAX_LAG_SAMP.
[9]:
t1 = give_time()
template_group.compute_intertemplate_cc(
distance_threshold=DISTANCE_THRESHOLD_KM,
n_stations=N_CLOSEST_STATIONS,
save_cc=False,
max_lag=MAX_LAG_SAMP,
compute_from_scratch=True,
)
t2 = give_time()
print(f"Computed inter-template CCs in {t2-t1:.2f}sec.")
True ../BPMF_data/2012/intertp_cc.h5 False
Computing the similarity matrix...
Computing the inter-template directional errors...
/home/ebeauce/software/Seismic_BPMF/BPMF/dataset.py:4624: RuntimeWarning: invalid value encountered in divide
unit_direction /= np.sqrt(np.sum(unit_direction**2, axis=1))[:, np.newaxis]
Computed inter-template CCs in 1.93sec.
[10]:
template_group.intertemplate_cc
[10]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 0.567785 | 0.286323 | 0.530515 | 0.119530 | 0.444778 | 0.304133 | 0.000000 | 0.0 | 0.751077 | 0.525963 | 0.768499 | 0.384494 | 0.000000 | 0.169807 |
| 1 | 0.567785 | 1.000000 | 0.289706 | 0.589208 | 0.144909 | 0.441921 | 0.311163 | 0.000000 | 0.0 | 0.556722 | 0.389535 | 0.544311 | 0.470420 | 0.000000 | 0.186365 |
| 2 | 0.286323 | 0.289706 | 1.000000 | 0.339150 | 0.165874 | 0.262199 | 0.204695 | 0.178083 | 0.0 | 0.285366 | 0.344129 | 0.278125 | 0.305763 | 0.000000 | 0.192427 |
| 3 | 0.530515 | 0.589208 | 0.339150 | 1.000000 | 0.154434 | 0.499107 | 0.336102 | 0.000000 | 0.0 | 0.539248 | 0.448403 | 0.523865 | 0.517872 | 0.000000 | 0.207463 |
| 4 | 0.119530 | 0.144909 | 0.165874 | 0.154434 | 1.000000 | 0.109366 | 0.130130 | 0.000000 | 0.0 | 0.118482 | 0.115195 | 0.111841 | 0.151186 | 0.000000 | 0.148202 |
| 5 | 0.444778 | 0.441921 | 0.262199 | 0.499107 | 0.109366 | 1.000000 | 0.302182 | 0.000000 | 0.0 | 0.416773 | 0.373156 | 0.460123 | 0.390779 | 0.000000 | 0.172668 |
| 6 | 0.304133 | 0.311163 | 0.204695 | 0.336102 | 0.130130 | 0.302182 | 1.000000 | 0.000000 | 0.0 | 0.340601 | 0.277798 | 0.312679 | 0.311202 | 0.000000 | 0.170985 |
| 7 | 0.000000 | 0.000000 | 0.178083 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.210255 | 0.000000 |
| 8 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 9 | 0.751077 | 0.556722 | 0.285366 | 0.539248 | 0.118482 | 0.416773 | 0.340601 | 0.000000 | 0.0 | 1.000000 | 0.499493 | 0.816776 | 0.421824 | 0.000000 | 0.176032 |
| 10 | 0.525963 | 0.389535 | 0.344129 | 0.448403 | 0.115195 | 0.373156 | 0.277798 | 0.000000 | 0.0 | 0.499493 | 1.000000 | 0.524332 | 0.412540 | 0.000000 | 0.212730 |
| 11 | 0.768499 | 0.544311 | 0.278125 | 0.523865 | 0.111841 | 0.460123 | 0.312679 | 0.000000 | 0.0 | 0.816776 | 0.524332 | 1.000000 | 0.475183 | 0.000000 | 0.188095 |
| 12 | 0.384494 | 0.470420 | 0.305763 | 0.517872 | 0.151186 | 0.390779 | 0.311202 | 0.000000 | 0.0 | 0.421824 | 0.412540 | 0.475183 | 1.000000 | 0.000000 | 0.173604 |
| 13 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.210255 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 |
| 14 | 0.169807 | 0.186365 | 0.192427 | 0.207463 | 0.148202 | 0.172668 | 0.170985 | 0.000000 | 0.0 | 0.176032 | 0.212730 | 0.188095 | 0.173604 | 0.000000 | 1.000000 |
[11]:
# set the threshold to consider two template as redundant
# this parameter is quite arbitrary and really depends on how much computation
# time you are ready to spend in the matched-filter search
# templates with very low correlation coefficients (~0.10) still detect
# many events in common
SIMILARITY_THRESHOLD = 0.50
[12]:
templates_filtered = []
tids_processed = set()
for tid in template_group.tids:
if tid in tids_processed:
continue
tt = template_group.tindexes.loc[tid]
similar = template_group.intertemplate_cc.loc[tid] > SIMILARITY_THRESHOLD
similar_tids = set(template_group.intertemplate_cc[similar].index)
# comment the following line for a more conservative linkage
similar_tids.difference_update(tids_processed)
n_similar = len(similar_tids)
if n_similar > 1:
print(f"Template {tid} is similar to: {similar_tids}")
best_tid = -10
best_unc = 10000000.0
for tid_sim in similar_tids:
tt_sim = template_group.tindexes.loc[tid_sim]
unc = np.sqrt(
template_group.templates[tt_sim].hmax_unc ** 2
+ template_group.templates[tt_sim].vmax_unc ** 2
)
if unc < best_unc:
best_unc = unc
best_tid = tid_sim
print(f"Keeping only Template {best_tid}")
## uncomment if you're using the more conservative linkage
#if best_tid in tids_processed:
# continue
tids_processed.update(similar_tids)
templates_filtered.append(
template_group.templates[
template_group.tindexes.loc[best_tid]
]
)
elif n_similar == 0:
print(
f"Problem with Template {tid}, it should at least be similar with" " itself"
)
else:
tids_processed.add(tid)
templates_filtered.append(template_group.templates[tt])
Template 0 is similar to: {0, 1, 3, 9, 10, 11}
Keeping only Template 1
Plot the similar templates
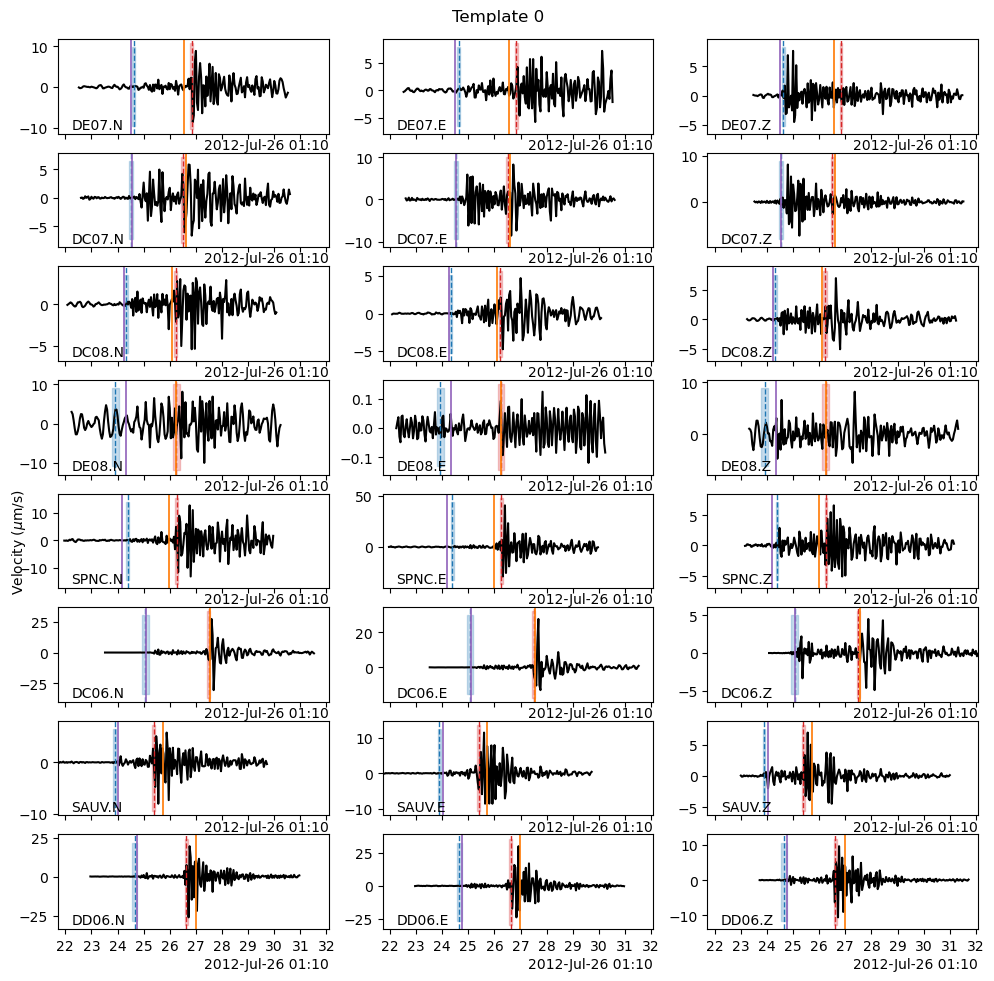
How good was our criterion to group similar templates together? Let’s check the waveforms of the similar templates. The previous cell told us that template 0 is similar to templates 1, 4, 11, 12 and 13.
[13]:
tid = 0
fig = template_group.templates[template_group.tindexes.loc[tid]].plot(figsize=(10, 10))
fig.suptitle(f"Template {tid}")
/home/ebeauce/software/Seismic_BPMF/BPMF/dataset.py:3173: UserWarning: no explicit representation of timezones available for np.datetime64
np.datetime64(ph_pick),
/home/ebeauce/software/Seismic_BPMF/BPMF/dataset.py:3195: UserWarning: no explicit representation of timezones available for np.datetime64
ph_pick = np.datetime64(
[13]:
Text(0.5, 0.98, 'Template 0')
[14]:
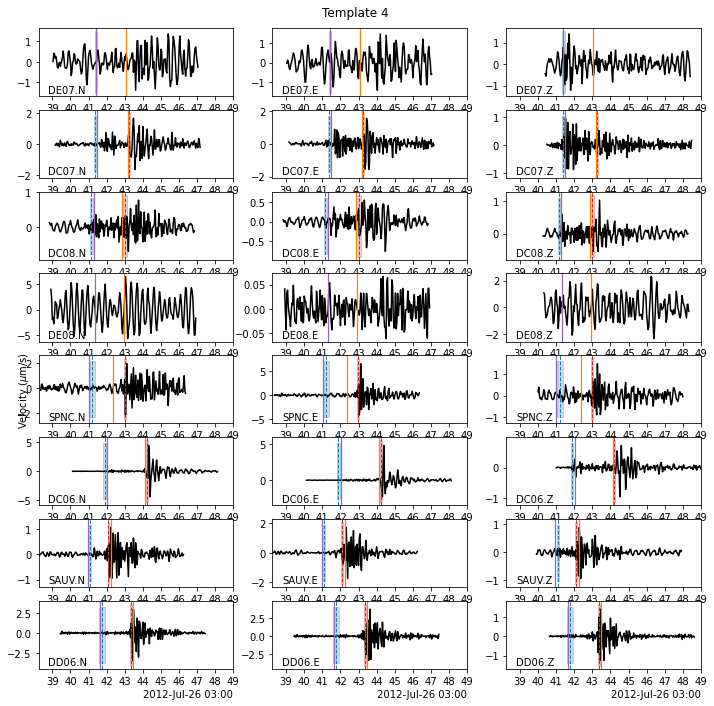
tid = 1
fig = template_group.templates[template_group.tindexes.loc[tid]].plot(figsize=(10, 10))
fig.suptitle(f"Template {tid}")
[14]:
Text(0.5, 0.98, 'Template 1')
Let’s plot the waveforms of all the templates similar to template 0 on SAUV.E .
[15]:
from scipy.signal import hilbert
similar_tids = [0, 1, 4, 11, 12, 13]
fig = plt.figure("waveforms_similar_templates", figsize=(15, 7))
ax = fig.add_subplot(111)
for tid in similar_tids:
tp = template_group.templates[template_group.tindexes.loc[tid]]
wav = tp.traces.select(station="SAUV", component="E")[0].data
norm = np.std(wav)
# align traces on max of envelope
time = np.arange(len(wav))
time -= np.abs(hilbert(wav)).argmax()
# time -= np.abs(wav).argmax()
if tid == 0:
ax.plot(time, wav/norm, color="k", lw=1.5)
else:
ax.plot(time, wav/norm, color="dimgrey", lw=0.75)
ax.set_xlabel("Time to max (samples)")
ax.set_ylabel("Velocity (AU)")
[15]:
Text(0, 0.5, 'Velocity (AU)')
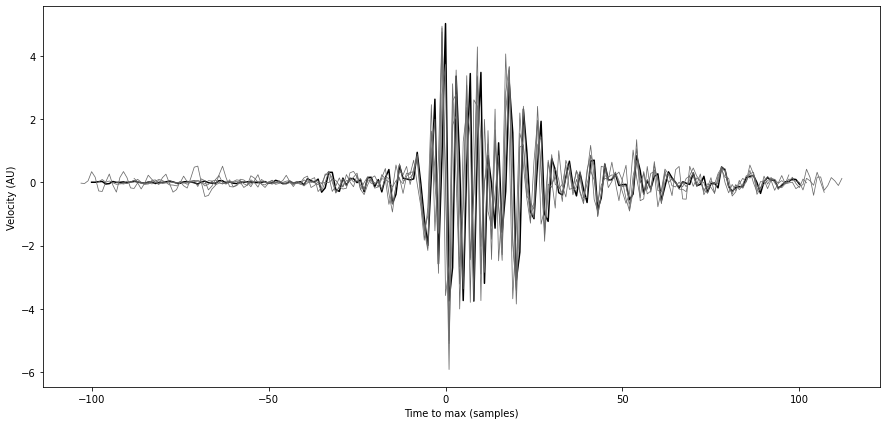
The similarity of these templates would make them detect the same events and thus, spending time on redundant computation and writing redundant info in databases.
Save the non-redundant templates in a database
[16]:
output_dir = os.path.join(BPMF.cfg.OUTPUT_PATH, DB_PATH_T)
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
for t, template in enumerate(templates_filtered):
tid = t
template.id = tid
template.set_aux_data({"tid": tid})
full_path = os.path.join(output_dir, f"template{tid}.h5")
template.write(
f"template{tid}.h5",
db_path=output_dir,
overwrite=True,
)