Backprojection of the Seismic Wavefield
In this notebook, we use the powerful deep neural network PhaseNet Zhu et al. 2019 to compute waveform features that are optimized for earthquake detection and location. The backprojection is done on these waveform features rather than the waveforms themselves. The efficient core backprojection routine used by BPMF is implemented in our python package `beampower <https://github.com/ebeauce/beampower>`__.
[1]:
import os
# choose the number of threads you want to limit the computation to
n_CPUs = 12
os.environ["OMP_NUM_THREADS"] = str(n_CPUs)
# os.environ["OMP_NUM_THREADS"] = str(n_CPUs) # export OMP_NUM_THREADS=4
# os.environ["OPENBLAS_NUM_THREADS"] = str(n_CPUs) # export OPENBLAS_NUM_THREADS=4
# os.environ["MKL_NUM_THREADS"] = str(n_CPUs) # export MKL_NUM_THREADS=6
# os.environ["VECLIB_MAXIMUM_THREADS"] = str(n_CPUs) # export VECLIB_MAXIMUM_THREADS=4
# os.environ["NUMEXPR_NUM_THREADS"] = str(n_CPUs) # export NUMEXPR_NUM_THREADS=6
import BPMF
import h5py as h5
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seisbench.models as sbm
import torch
from BPMF.data_reader_examples import data_reader_mseed
from obspy import UTCDateTime as udt
from time import time as give_time
from scipy.signal import resample_poly
[2]:
# %config InlineBackend.figure_formats = ["svg"]
plt.rcParams["svg.fonttype"] = "none"
[3]:
# PROGRAM PARAMETERS
# DEVICE: is "cpu" or "gpu" depending on whether you want to use Nvidia GPUs or not
DEVICE = "cpu"
# PHASES: list of seismic phases to use for backprojection
PHASES = ["P", "S"]
# N_MAX_STATIONS: the maximum number of stations used for stacking (e.g. the closest to a given grid point)
# note: this parameter is irrelevant in this example with only 8 stations, but it is important when
# using large seismic networks
N_MAX_STATIONS = 10
NETWORK_FILENAME = "network.csv"
TT_FILENAME = "tts.h5"
OUTPUT_DB_FILENAME = "raw_bp.h5"
DATA_FOLDER = "preprocessed_2_12"
# PhaseNet was trained for 100Hz data, however, it shows good performances
# for other sampling rates. Using 25Hz data causes PhaseNet to "smooth" in time
# its output, which is actually good for the purpose of backprojection.
# Also, see Shi et al., 2024: From labquakes to megathrusts: Scaling deep learning based pickers over 15 orders of magnitude
# for how to use "time rescaling" to our advantage
UPSAMPLING_BEFORE_PN_DETECTION = 1
DOWNSAMPLING_BEFORE_PN_DETECTION = 1
# The PhaseNet model distributed in seisbench returns a 3-component time series: (noise, p-wave, s-wave)
PHASENET_CHANNEL_INDEXES = np.array([1, 2])
# Component names for the BPMF.template_search.WaveformTransform instance
TRANSFORM_COMPONENT_NAMES = ["P", "S"]
Load metadata
[4]:
# load network metadata
net = BPMF.dataset.Network(NETWORK_FILENAME)
net.read()
net.metadata
[4]:
| station_id | networks | stations | longitude | latitude | elevation_m | depth_km | |
|---|---|---|---|---|---|---|---|
| stations | |||||||
| DD06 | YH.DD06 | YH | DD06 | 30.317770 | 40.623539 | 182.0 | -0.182 |
| DE08 | YH.DE08 | YH | DE08 | 30.406469 | 40.748562 | 31.0 | -0.031 |
| SPNC | YH.SPNC | YH | SPNC | 30.308300 | 40.686001 | 190.0 | -0.190 |
| DC08 | YH.DC08 | YH | DC08 | 30.250130 | 40.744438 | 162.0 | -0.162 |
| DC06 | YH.DC06 | YH | DC06 | 30.265751 | 40.616718 | 555.0 | -0.555 |
| SAUV | YH.SAUV | YH | SAUV | 30.327200 | 40.740200 | 170.0 | -0.170 |
| DE07 | YH.DE07 | YH | DE07 | 30.411539 | 40.679661 | 40.0 | -0.040 |
| DC07 | YH.DC07 | YH | DC07 | 30.242170 | 40.667080 | 164.0 | -0.164 |
[5]:
tts = BPMF.template_search.TravelTimes(
TT_FILENAME,
tt_folder_path=BPMF.cfg.MOVEOUTS_PATH
)
# # uncomment the following line if you want to run the backprojection with the downsampled grid (if you ran the "bonus" section of the previous notebook!)
# sparse_grid_indexes = np.load(
# os.path.join(BPMF.cfg.MOVEOUTS_PATH, f"sparse_grid_indexes_0.08.npy")
# )
# uncomment the following line if you want to run the backprojection with the entire grid
sparse_grid_indexes = None
# calling tts.read() reads the travel times and stores them in the tts.travel_times attribute
tts.read(
PHASES, source_indexes=sparse_grid_indexes, read_coords=True, stations=net.stations
)
[6]:
# check out tts.travel_times, it's a pandas.DataFrame
tts.travel_times
[6]:
| P | S | |
|---|---|---|
| DC06 | [6.176006, 6.1575384, 6.142126, 6.129763, 6.12... | [10.704086, 10.671984, 10.645192, 10.623703, 1... |
| DC07 | [5.5714087, 5.5575557, 5.546636, 5.538468, 5.5... | [9.65964, 9.635547, 9.616555, 9.602348, 9.5918... |
| DC08 | [5.134612, 5.1179695, 5.104504, 5.094062, 5.08... | [8.89952, 8.870467, 8.846935, 8.828664, 8.8151... |
| DD06 | [6.1245594, 6.090376, 6.059061, 6.0306463, 6.0... | [10.62153, 10.562013, 10.507493, 10.458022, 10... |
| DE07 | [6.120203, 6.057422, 5.9970937, 5.9392962, 5.8... | [10.619495, 10.510359, 10.405491, 10.305027, 1... |
| DE08 | [5.763296, 5.698576, 5.636388, 5.576819, 5.519... | [9.99645, 9.884211, 9.77636, 9.67305, 9.574434... |
| SAUV | [5.3968863, 5.3549123, 5.316128, 5.2806077, 5.... | [9.356273, 9.283206, 9.215697, 9.153876, 9.097... |
| SPNC | [5.6131864, 5.5791845, 5.5483456, 5.520706, 5.... | [9.73132, 9.672194, 9.618565, 9.5704975, 9.528... |
[7]:
# we are interested in travel times in samples, given that the sampling rate is BPMF.cfg.SAMPLING_RATE_HZ
# we set remove_tt_seconds=True so that tts.travel_times is deleted to free space
tts.convert_to_samples(BPMF.cfg.SAMPLING_RATE_HZ, remove_tt_seconds=True)
[8]:
# check out tts.travel_times_samp, it's a pandas.DataFrame
tts.travel_times_samp
[8]:
| P | S | |
|---|---|---|
| DC06 | [154, 154, 153, 153, 153, 153, 152, 152, 153, ... | [267, 266, 266, 265, 265, 265, 264, 264, 265, ... |
| DC07 | [139, 139, 138, 138, 138, 138, 138, 138, 139, ... | [241, 241, 240, 240, 239, 240, 240, 240, 241, ... |
| DC08 | [128, 128, 127, 127, 127, 127, 127, 127, 127, ... | [222, 221, 221, 220, 220, 220, 220, 220, 221, ... |
| DD06 | [153, 152, 151, 150, 150, 149, 149, 148, 148, ... | [265, 264, 262, 261, 260, 259, 258, 257, 257, ... |
| DE07 | [153, 151, 150, 148, 147, 145, 144, 143, 142, ... | [265, 262, 260, 257, 255, 253, 250, 248, 247, ... |
| DE08 | [144, 142, 141, 139, 138, 136, 135, 134, 133, ... | [250, 247, 244, 242, 239, 237, 234, 232, 230, ... |
| SAUV | [135, 134, 133, 132, 131, 130, 130, 129, 129, ... | [234, 232, 230, 229, 227, 226, 225, 224, 223, ... |
| SPNC | [140, 139, 138, 138, 137, 137, 136, 136, 135, ... | [243, 242, 240, 239, 238, 237, 236, 236, 235, ... |
Load the data
The following piece of code is written to process a single day, but you could loop over as many days as necessary.
[9]:
date_list = net.datelist()
print("Days to process: ", date_list)
Days to process: DatetimeIndex(['2012-07-26 00:00:00+00:00'], dtype='datetime64[ns, UTC]', freq='D')
[10]:
# this could be written as a loop:
#for date in date_list:
date = date_list[0]
date = pd.Timestamp(date)
date_str = date.strftime("%Y-%m-%d")
data_root_folder = os.path.join(BPMF.cfg.INPUT_PATH, str(date.year), date.strftime("%Y%m%d"))
t_start_day = give_time()
print(f"Reading data for {date_str}")
# -------------------------------------------
# Load the data
# -------------------------------------------
data = BPMF.dataset.Data(
date,
data_root_folder,
data_reader_mseed,
duration=24.0 * 3600.0,
sampling_rate=BPMF.cfg.SAMPLING_RATE_HZ,
)
data.read_waveforms(data_folder=DATA_FOLDER)
print(data.traces.__str__(extended=True))
Reading data for 2012-07-26
24 Trace(s) in Stream:
YH.DD06..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE08..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SPNC..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC08..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC06..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SAUV..HHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC08..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE08..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SPNC..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC06..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SAUV..HHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE07..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC07..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DD06..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC07..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE07..BHE | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DD06..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SAUV..HHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC08..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE08..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.SPNC..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC06..BHZ | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DE07..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
YH.DC07..BHN | 2012-07-26T00:00:00.000000Z - 2012-07-27T00:00:00.000000Z | 25.0 Hz, 2160001 samples
[11]:
# compute data availability
data.set_availability(net.stations)
Compute the waveform features
The goal is to compute the waveform_features numpy.ndarray with dimension (n_stations, n_channels, n_times).
Here, we demonstrate how a single-station deep neural network detector can be turned into an array detector with backprojection.
[12]:
def ml_detector(x, chunk_size=3000):
"""ML-based seismic phase detector using PhaseNet.
For maximum flexibility, all interfacing with phase pickers is done through
wrapper functions like this one. This function must behave like:
`y = f(x)`,
where `y` are the time series of P- and S-wave probabilities. This function must
include all preprocessing steps that may be required, like chunking and normalization.
Parameters
----------
x : np.ndarray
Seismograms, shape (n_stations, n_channels=3, n_times).
chunk_size : int, optional
Size of the seismograms, in samples, used in the training of the ML model.
Default is 3000 (30 seconds at 100 Hz).
Returns
-------
ps_proba_time_series : np.ndarray
Time series of P- and S-wave probabilities, shape (n_stations, n_phases, n_times).
The first channel, `ps_proba_time_series[:, 0, :]` is the P-wave probability,
and the second, `ps_proba_time_series[:, 1, :]`, is the S-wave probability.
"""
_ml_detector = sbm.PhaseNet.from_pretrained("original")
_ml_detector.eval()
if DEVICE == "gpu":
_ml_detector.to("cuda")
x = BPMF.utils.normalize_batch(x, normalization_window_sample=chunk_size)
with torch.no_grad():
x = torch.from_numpy(x).float().to("cuda" if DEVICE == "gpu" else "cpu")
ps_proba_time_series = _ml_detector(x)
# remove channel 0, which is probability of noise
return ps_proba_time_series[:, PHASENET_CHANNEL_INDEXES, :].cpu().detach().numpy()
[13]:
# get the data in a numpy.ndarray
data_arr = data.get_np_array(net.stations)
[14]:
if ((UPSAMPLING_BEFORE_PN_DETECTION > 1) or (DOWNSAMPLING_BEFORE_PN_DETECTION > 1)):
data_arr = resample_poly(
data_arr,
UPSAMPLING_BEFORE_PN_DETECTION,
DOWNSAMPLING_BEFORE_PN_DETECTION,
axis=-1
)
waveform_features = ml_detector(data_arr)
if ((UPSAMPLING_BEFORE_PN_DETECTION > 1) or (DOWNSAMPLING_BEFORE_PN_DETECTION > 1)):
waveform_features = resample_poly(
waveform_features,
DOWNSAMPLING_BEFORE_PN_DETECTION,
UPSAMPLING_BEFORE_PN_DETECTION,
axis=-1
)
[15]:
print("The shape of waveform_features is: ", waveform_features.shape)
The shape of waveform_features is: (8, 2, 2160000)
The BPMF.template_search.WaveformTransform class allows us to manipulate ‘waveform_transform’ like an obspy.Stream
[16]:
waveform_transform = BPMF.template_search.WaveformTransform(
waveform_features,
net.stations,
TRANSFORM_COMPONENT_NAMES,
data.date,
BPMF.cfg.SAMPLING_RATE_HZ,
)
[30]:
STATION_NAME = "DC06"
OT = udt("2012-07-26T08:07:48")
OFFSET_OT_SEC = 0.
DURATION_SEC = 100.
P_COLOR = "C0"
S_COLOR = "C1"
LW = 1.0
waveform_transform_event = waveform_transform.slice(
OT - OFFSET_OT_SEC,
duration=DURATION_SEC,
stations=net.stations,
)
event_data = data.traces.select(station=STATION_NAME, component="Z").slice(
OT - OFFSET_OT_SEC, OT - OFFSET_OT_SEC + DURATION_SEC
)[0]
transformed_data_p = waveform_transform_event.transform.select(station=STATION_NAME, component="P")[0]
transformed_data_s = waveform_transform_event.transform.select(station=STATION_NAME, component="S")[0]
print(f"Selected station is {STATION_NAME}")
fig = plt.figure("waveform_feature", figsize=(15, 5))
ax = fig.add_subplot(111)
ax.set_title(f"Waveform + PhaseNet prediction on {STATION_NAME}")
ax.plot(event_data.times(), event_data.data, color="k")
ax.set_ylabel("Velocity [m/s]")
axb = ax.twinx()
axb.plot(transformed_data_p.times(), transformed_data_p.data, lw=1.5, color=P_COLOR, label="P-arrival probability")
axb.plot(transformed_data_s.times(), transformed_data_s.data, lw=1.5, color=S_COLOR, label="S-arrival probability")
axb.set_ylabel("Waveform Feature")
axb.set_ylim(-1., +1.0)
axb.legend(loc="lower right")
ax.set_xlabel("Time (seconds)")
Selected station is DC06
[30]:
Text(0.5, 0, 'Time (seconds)')
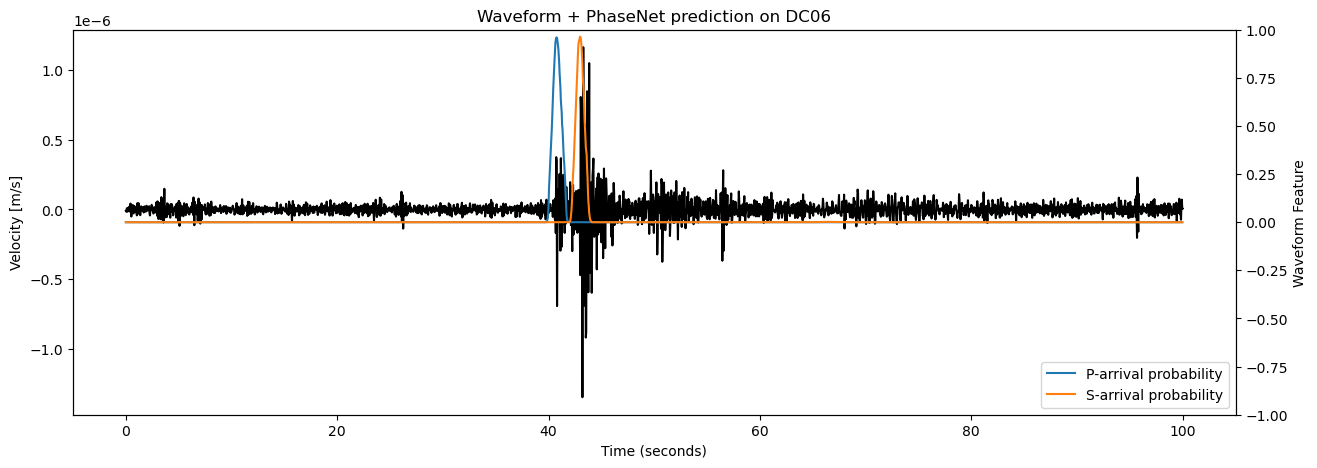
See that the number of channels in waveform_features is only 2. This is because phasenet returned a time series of P-arrival probability waveform_features[:, 0, :] and a time series of S-arrival probability waveform_features[:, 1, :].
Initialize the Beamformer instance
The initialization of the Beamformer instance only requires the table of travel times and the corresponding source coordinates. The sampling rate is used to convert the travel time table, in seconds, to a moveout table, in samples. Note that the moveouts are all taken relative to the first P-wave arrival for each source.
[31]:
# initialize the Beamformer instance
# most of the important attributes can be initialized here but also later (see following cells)
# we set moveouts_relative_to_first=True so that, for a given source, the moveouts are defined as the travel
# times relative to the first network-wide arrival (e.g. P-wave on the closest station)
bf = BPMF.template_search.Beamformer(
phases=PHASES,
moveouts_relative_to_first=True,
)
Inform the Beamformer instance of the data and metadata
Before using the Beamformer instance to backproject the wavefield, we need to set a number of important attributes to the instance. First, we attach the Data instance to the Beamformer instance so that Beamformer’s methods can read the Data instance’s attributes. Second, we attach the Network instance corresponding to the set of stations that we are going to use for this backprojection.
N.B.: The Network instance can be a subset of the total network represented in the travel time table! It means that you can initialize the Beamformer instance once and for all and then process different time periods when the operating stations might be a subset of the total network.
[32]:
# attach the Data instance
bf.set_data(data)
# attach the Network instance
bf.set_network(net)
# attach the TravelTimes instance
bf.set_travel_times(tts)
Define the phase-specific weights
We recall that the definition of a beam is:
where \(k\) is the source (grid point) index, \(\mathcal{U}_{s, c}(t)\) is the waveform feature at station \(s\), channel \(c\) and time \(t\), and \(\tau_{s, p}^{(k)}\) is the moveout at station \(s\), seismic phase \(p\) and source \(k\). For a given \(p\), the moveout is the same of all channels of the same station \(s\). Therefore, the quantity \(\sum_{c} \mathcal{U}_{s, c}(t)\) can be computed once and for all instead of re-computing it for each source.
Note: In this tutorial, we used PhaseNet to compute the waveform features \(\mathcal{U}_{s,c}\). Therefore, our features have 2 channels: the P-wave probability channel and the S-wave probability channel.
For a given seismic phase, say the P-wave, we may not want to use all channels. For example, we may want to use only the vertical channel, or, with the waveform_features previously computed with phasenet, we only want to use the P-wave probability channel. Thus, the quantity we can compute once and for all is:
\(\alpha_{s, c, p}\) is the phase-specific weight at station \(s\) and channel \(c\) and for phase \(p\).
In this example, the appropriate phase-specific weights are:
[33]:
weights_phases = np.ones((waveform_features.shape[:-1]) + (2,), dtype=np.float32)
weights_phases[:, 0, 1] = 0.0 # S-wave weights to zero for channel 0
weights_phases[:, 1, 0] = 0.0 # P-wave weights to zero for channel 1
print("The shape of weights_phases is: ", weights_phases.shape)
The shape of weights_phases is: (8, 2, 2)
[34]:
# attach the phase-specific weights to the NetworkResponse instance
bf.set_weights(weights_phases=weights_phases)
Define the source-specific weights
When using a grid covering a large geographical region, all stations may not be relevant to every source (grid point). Small earthquakes occurring at one end of the region are unlikely to be recorded by stations at the other end of the region. In order to only use the relevant data to each source, we define the source-specific weights \(\beta_{k, s}\) and modify the definition of the beam:
The source-specific weights \(\beta_{k, s}\) can be used to restrict the source-receiver distances included in the computation of \(b_k(t)\), but also to downweight some stations. The simplest option in BPMF is to set to 0 all source-station weights beyond the N_MAX_STATIONS closest stations. In this example, we only have 8 stations and are studying a small region so all weights are 1.
Using normalize=True in the following forces: \(\sum_s \beta_{k, s} = 1\). Given this normalization, the maximum possible beam is 2 (the number of different seismic phases).
[35]:
bf.set_weights_sources(num_closest_stations=N_MAX_STATIONS, method="closest_stations", normalize=True)
# if, instead, you are interested in a more sophisticated weighting scheme using all stations within a certain distance,
# you can use the following, with max_moveout being a proxy for distance
# if a grid point has less than n_min_stations stations within the requested max_moveout, all weights are set to 0 and the grid point is ignored
# bf.set_weights_sources(max_moveout=100., method="max_moveout", n_min_stations=4, weight_station_density=True, normalize=True)
Run the backprojection
We are now ready to run the backprojection at all times \(t\):
[36]:
#
bf.backproject(waveform_features, device=DEVICE, reduce="max")
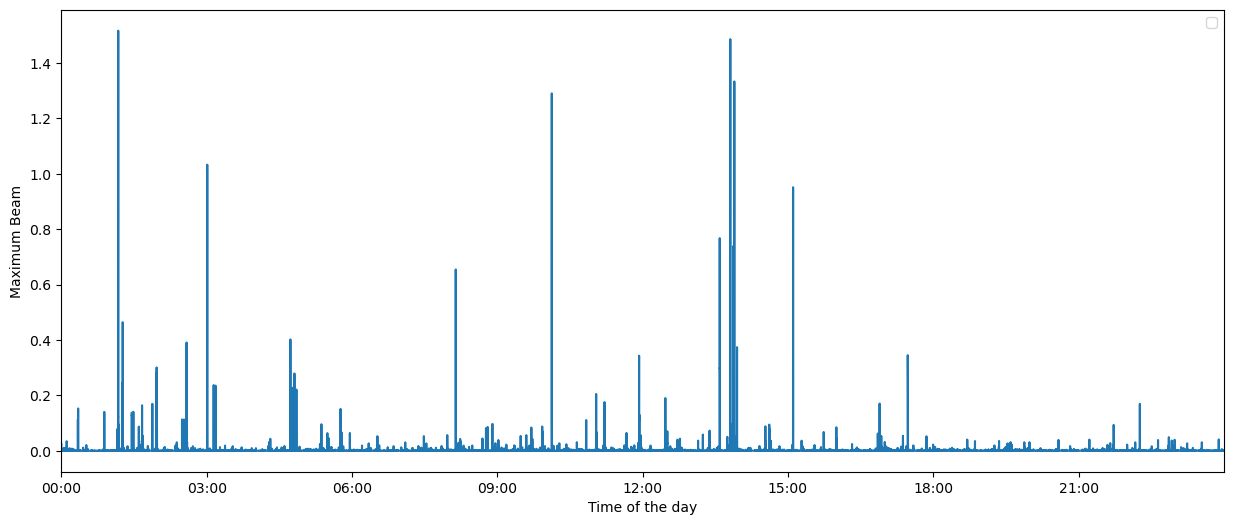
After calling bf.backproject with reduce="max", we have computed \(b^*(t)\) and \(k^*(t)\). These can be found at bf.maxbeam and bf.maxbeam_sources.
Let’s plot \(b^*(t)\).
[37]:
fig = bf.plot_maxbeam(figsize=(15, 6))
fig.set_facecolor("w")
/home/ebeauce/software/Seismic_BPMF/BPMF/template_search.py:1008: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
ax.legend(loc="upper right")
/home/ebeauce/software/Seismic_BPMF/BPMF/template_search.py:1016: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
ax.legend(loc="upper right")
Define the earthquake detections
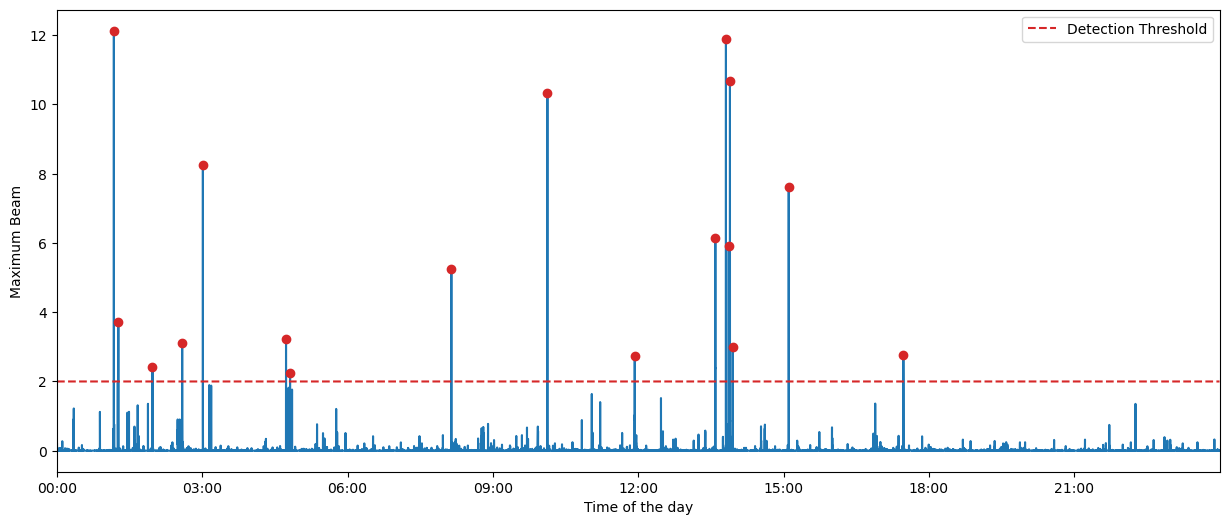
Detecting earthquakes based on the maximum beam computed above relies on the somewhat arbitrary task of defining a detection threshold. When stacking many time series, we may expect the sum to nearly be normally distributed according to the central limit theorem. However, when using PhaseNet to compute the waveform features, the distribution of the maximum beam is often far from a normal distribution and the definition of a detection threshold based on gaussian p-values is not a valid approach.
The detection threshold used in this example was derived purely empirically by a trial-and-error procedure, manually checking the presence of false positive detections. Here, we use a threshold = 0.33, that is, 16.5% of the maximum possible value of 2, given the weight normalization. As you will see in the following cells, this choice is quite conservative; don’t hesitate playing with the threshold and lowering it.
To avoid declaring multiple detections for a single event, we also define a minimum inter-event time. Backprojection is fundamentally not great at resolving multiple events closely occurring in time because of the important trade-off between location uncertainty vs origin time uncertainty. Thus, we choose a minimum inter-event time of 1 minute. Later, template matching will allow us to improve our inter-event time resolution.
[39]:
MINIMUM_INTEREVENT_TIME_SEC = 60.0
detection_threshold = 0.33 * np.ones(len(bf.maxbeam), dtype=np.float32)
detections, peak_indexes, source_indexes = bf.find_detections(
detection_threshold, MINIMUM_INTEREVENT_TIME_SEC
)
Extracted 15 events.
Let’s see which peaks resulted in earthquake detections.
[25]:
fig = bf.plot_maxbeam(figsize=(15, 6))
fig.set_facecolor("w")
At this stage, we could save the metadata of each detected event and go to the next notebook, but we will first look at the waveforms of the detected events.
Extract the detected events from the continuous data
Each detected earthquake is returned as an instance of the BPMF.dataset.Event class.
[40]:
# event extraction parameters
# PHASE_ON_COMP: dictionary defining which moveout we use to extract the waveform
PHASE_ON_COMP = {"N": "S", "1": "S", "E": "S", "2": "S", "Z": "P"}
# OFFSET_PHASE: dictionary defining the time offset taken before a given phase
# for example OFFSET_PHASE["P"] = 1.0 means that we extract the window
# 1 second before the predicted P arrival time
OFFSET_PHASE = {"P": 1.0, "S": 4.0}
# TIME_SHIFTED: boolean, if True, use moveouts to extract relevant windows
TIME_SHIFTED = True
t1 = give_time()
for i in range(len(detections)):
detections[i].read_waveforms(
BPMF.cfg.TEMPLATE_LEN_SEC,
phase_on_comp=PHASE_ON_COMP,
offset_phase=OFFSET_PHASE,
time_shifted=TIME_SHIFTED,
data_folder=DATA_FOLDER,
)
t2 = give_time()
print(
f"{t2-t1:.2f}sec to read the waveforms for all {len(detections):d} detections."
)
4.11sec to read the waveforms for all 15 detections.
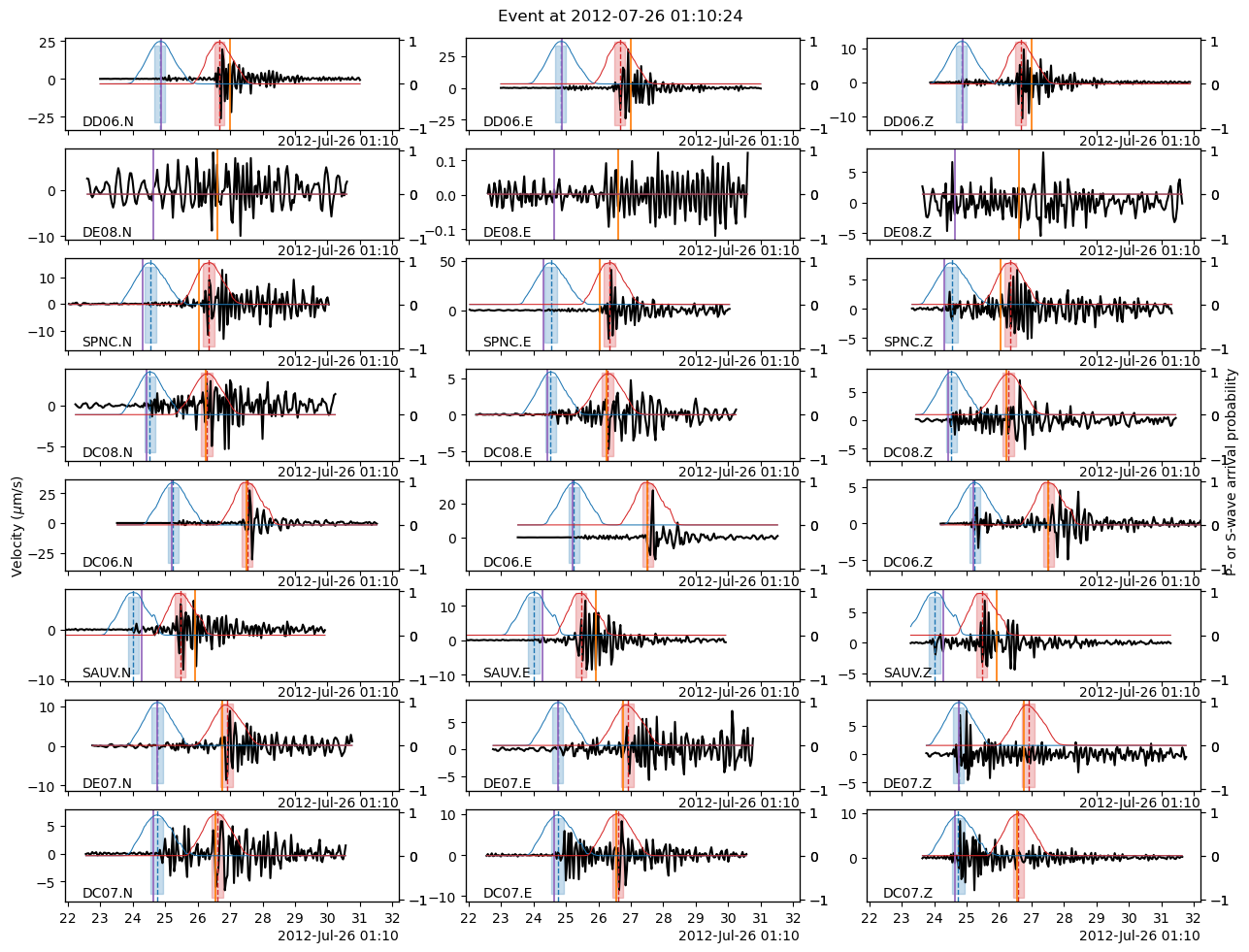
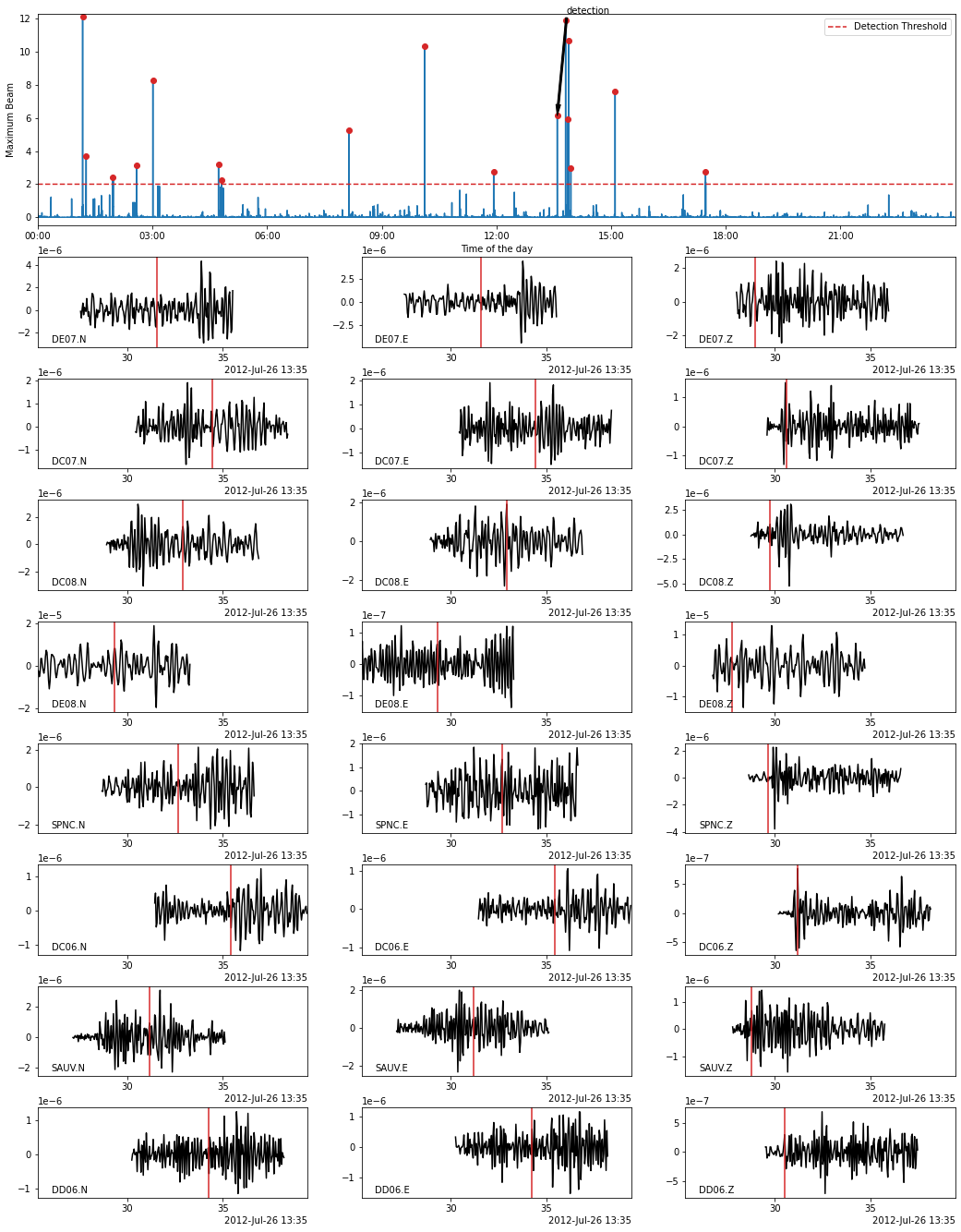
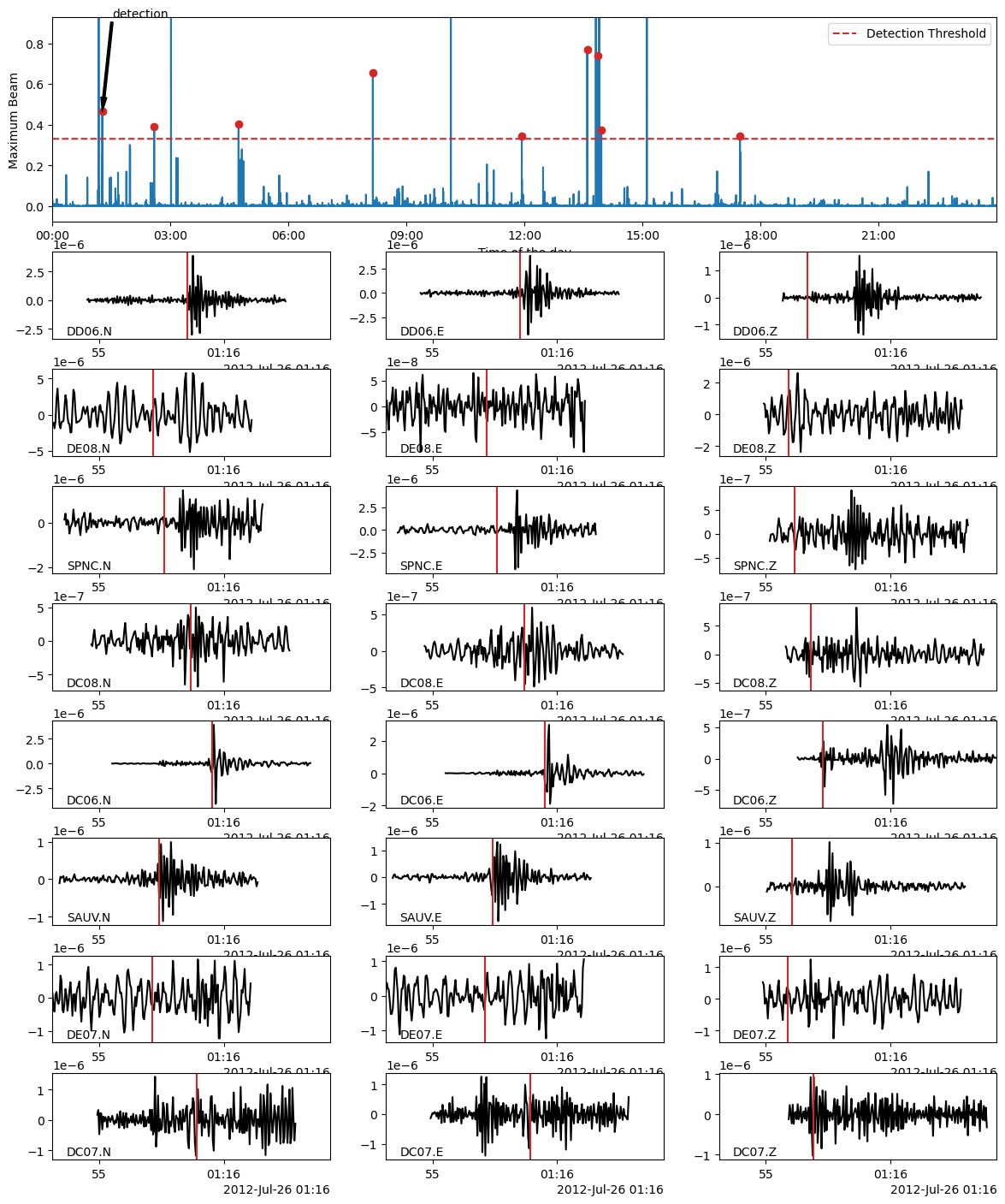
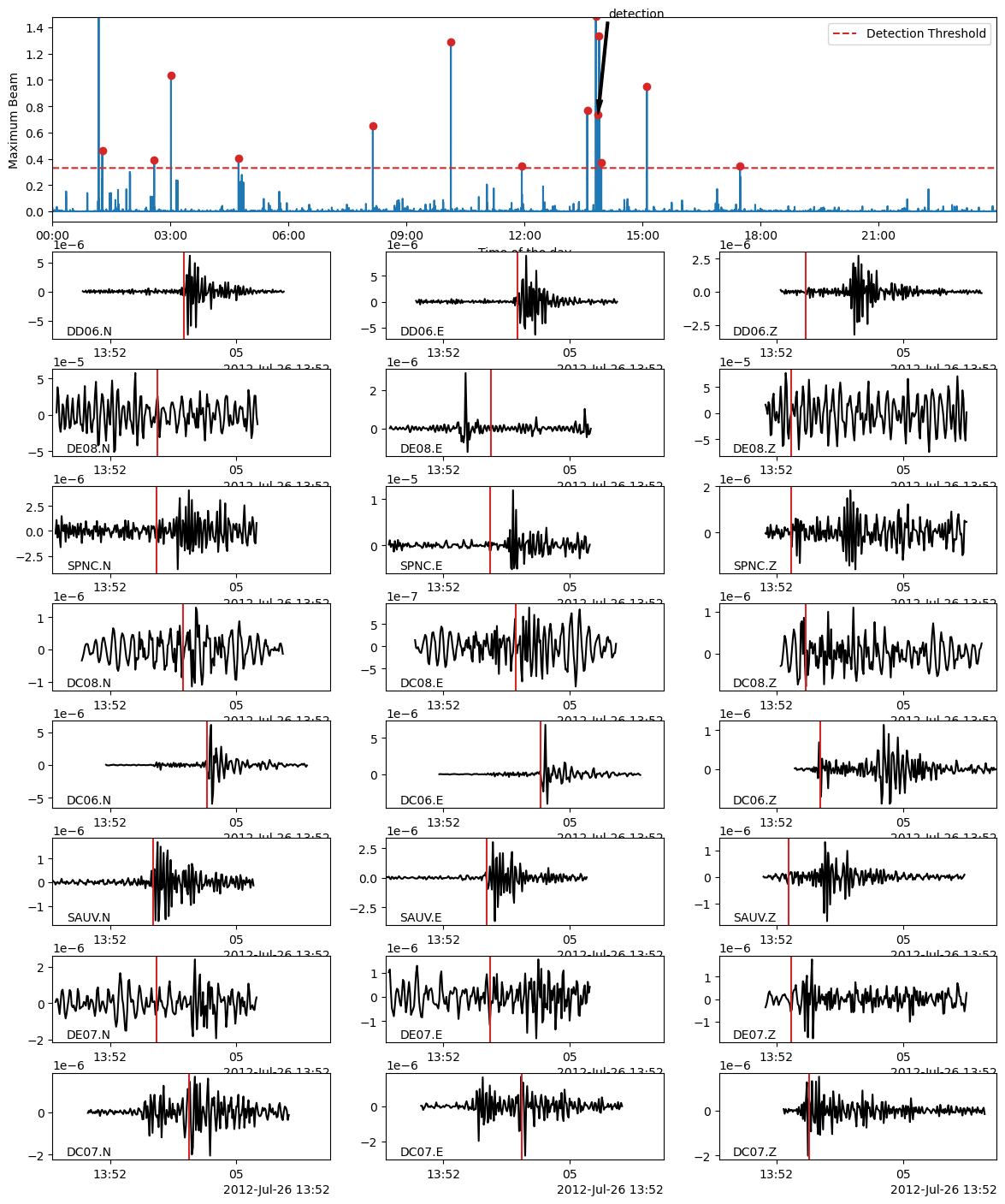
In the following, we use the Beamformer method to plot the detected earthquakes (only works after calling read_waveform with each detection, see above cell). Because we declared in PHASE_ON_COMP using the S wave on the horizontal components and the P wave on the vertical components, the red vertical lines on the following plots show the predicted S-wave arrival on the horizontal components and the P-wave arrival on the vertical components.
[42]:
fig = bf.plot_detection(detections[0], figsize=(12, 15))
fig.set_facecolor("w")
[43]:
fig = bf.plot_detection(detections[1], figsize=(12, 15))
fig.set_facecolor("w")
[44]:
fig = bf.plot_detection(detections[10], figsize=(12, 15))
fig.set_facecolor("w")
Store the metadata of the detected earthquakes in a database
By calling the Event.write method for each detection, we save their metadata in a hdf5 file located at BPMF.cfg.OUTPUT_PATH/OUTPUT_DB_FILENAME. Each event is stored in a separate hdf5 group with name defined as detections[i].id.
[45]:
# ---------------------------------------------------------
# Save detections
# ---------------------------------------------------------
for i in range(len(detections)):
detections[i].write(
OUTPUT_DB_FILENAME,
db_path=BPMF.cfg.OUTPUT_PATH,
gid=detections[i].id
)
BONUS: Phase picking using the pre-computed WaveformTransform
In this tutorial, precise phase picking is mainly covered in the next notebook, 6_relocate.ipynb, but in an actual workflow applied to a very long time period, computation must be optimized and running the phase picker twice would waste computation time with redundant information (unless you really want to re-run the phase picker on different pre-processed data). The following shows an example of how to re-use WaveformTransform to quickly produce P- and S-wave picks.
[46]:
def pick_ps_phases(event, network=net):
print(f"Picking P- and S-wave arrivals on {event.id}")
event.stations = network.stations
event.set_arrival_times_from_moveouts(verbose=0)
# attach pre-computed phase probabilities
offset_ot = 10.
DURATION_SEC = 120.
SEARCH_WINDOW_SEC = 3.
PHASE_ON_COMP = {"N": "S", "1": "S", "E": "S","2": "S", "Z": "P"}
COMPONENT_ALIASES = {"N": ["N", "1"], "E": ["E", "2"], "Z": ["Z"]}
waveform_transform_event = waveform_transform.slice(
event.origin_time - offset_ot,
duration=DURATION_SEC,
stations=event.stations,
)
event.pick_PS_phases(
None,
DURATION_SEC,
phase_on_comp=PHASE_ON_COMP,
data_folder=DATA_FOLDER,
component_aliases=COMPONENT_ALIASES,
threshold_P=0.1,
threshold_S=0.1,
upsampling=1,
downsampling=1,
use_apriori_picks=True,
search_win_sec=SEARCH_WINDOW_SEC,
phase_probability_time_series=waveform_transform_event,
keep_probability_time_series=True,
offset_ot=offset_ot
)
# update moveouts to match the new stations
for sta in event.stations:
if sta not in event.moveouts.index:
event.moveouts.loc[sta] = [0.0, 0.0]
return
[47]:
_ = list(map(pick_ps_phases, detections))
Picking P- and S-wave arrivals on 20120726_011024.280000
Picking P- and S-wave arrivals on 20120726_011555.880000
Picking P- and S-wave arrivals on 20120726_023502.160000
Picking P- and S-wave arrivals on 20120726_030040.880000
Picking P- and S-wave arrivals on 20120726_044340.160000
Picking P- and S-wave arrivals on 20120726_080827.360000
Picking P- and S-wave arrivals on 20120726_100725.640000
Picking P- and S-wave arrivals on 20120726_115536.760000
Picking P- and S-wave arrivals on 20120726_133527.760000
Picking P- and S-wave arrivals on 20120726_134834.840000
Picking P- and S-wave arrivals on 20120726_135200.480000
Picking P- and S-wave arrivals on 20120726_135333.600000
Picking P- and S-wave arrivals on 20120726_135656.000000
Picking P- and S-wave arrivals on 20120726_150621.480000
Picking P- and S-wave arrivals on 20120726_172821.680000
[49]:
idx = 0
detections[idx].plot(plot_probabilities=True, figsize=(13, 10)).show()
/tmp/ipykernel_198354/2915024177.py:2: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
detections[idx].plot(plot_probabilities=True, figsize=(13, 10)).show()